概要
- ソーシャルメディアプラットフォームは、プライバシーの懸念があるにもかかわらず、ユーザーデータを企業に販売して生成モデルのトレーニングを行っています。
- Meta、Reddit、Tumblr、WordPress.comなどのプラットフォームは、トレーニング用のデータライセンス契約に積極的に参加しています。
- ユーザーは、プライバシー設定の調整、共有のオプトアウト、オンラインで投稿する内容に注意するなど、データを保護するための小さな措置を講じることができます。
ソーシャルメディア企業がユーザーデータを収益化するための最新の手段の1つは、企業との取引です。しかし、一般ユーザーが自分のデータとコンテンツを保護するためにできることはあるのでしょうか?
ソーシャルメディアプラットフォームが企業と取引を結ぶ
生成モデルをトレーニングするためにソーシャルメディアデータを使用することは物議を醸す動きでしたが、このことがソーシャルメディア企業がユーザーデータを配布するのを妨げているようには見えません。
Metaはすでに、2023年のMeta Connectで発表された生成機能のトレーニングにソーシャルメディアデータを使用しています。これには、MetaとWhatsAppでAI生成のステッカーを作成する機能などが含まれます。
Metaの製品管理ディレクターであるマイク・クラーク氏は、Meta Newsroomの投稿で次のように述べています。
「InstagramとFacebookから共有された公開投稿(写真とテキストを含む)は、Connectで発表した機能の基盤となる生成モデルのトレーニングに使用されたデータの一部でした。」
この傾向は2024年も減速しなさそうです。ロイターによると、RedditはGoogleと取引を結び、ソーシャルメディアプラットフォームのコンテンツをモデルのトレーニングに利用できるようにしました。
2024年2月22日に提出されたRedditのIPOのためのS-1提出書類は、同社がライセンス契約を検討していることを確認しています。提出書類には次のように記載されています。
「Redditデータは、現在のテクノロジーと多くのLLMの構築の基礎的な部分です。Redditの大規模な会話データと知識のコーパスは、LLMのトレーニングと改善に引き続き役割を果たすと考えています。」
LLMをトレーニングするために、「サードパーティが当社のプラットフォームから履歴データとリアルタイムデータを検索、分析、表示するためのアクセスをライセンスできるようにする初期段階にあります」と明記しています。
MetaとRedditはソーシャルメディアの最大手ですが、AIのトレーニングにソーシャルメディアデータを使用しているのはこれらのプラットフォームだけではありません。404 Mediaのレポートによると、TumblrとWordPress.comはMidjourneyとOpenAIにユーザーデータを販売する準備をしています。
プラットフォームがトレーニングのためにソーシャルメディアデータを販売するのを阻止できますか?
Facebook、Instagram、Reddit、Tumblr、WordPress.comを使用している場合、公開コンテンツはすでにLLMのトレーニングに使用されている可能性があります。
たとえば、ワシントン・ポストの検索ツールを使用して、Bardのトレーニングの一部として使用されたGoogleのC4データセットに含まれていたサイトを確認すると、Reddit.comが790万トークンを占めていることがわかります。
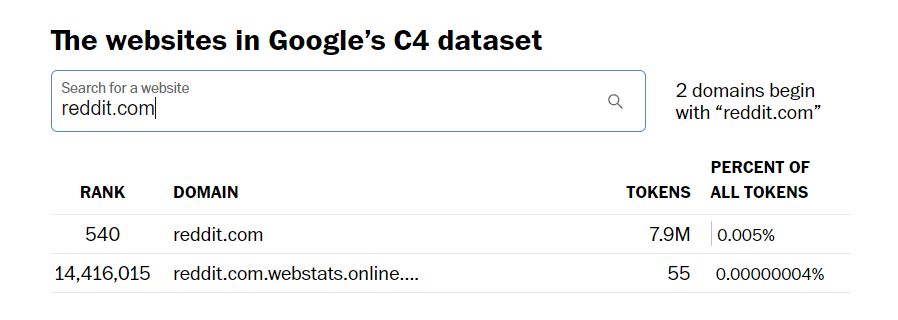
Tumblr.comは160万トークンを占めています。WordPress.comを使用している私自身の小さなウェブサイトは14,000トークンを占めていました。つまり、小さな個人的なブログもデータセットに含まれていた可能性があります。
企業とソーシャルメディア企業との間の継続的な取引により、ライセンス契約は、このデータが単にWebからスクレイピングされるのではなく、積極的に販売されることを意味します。
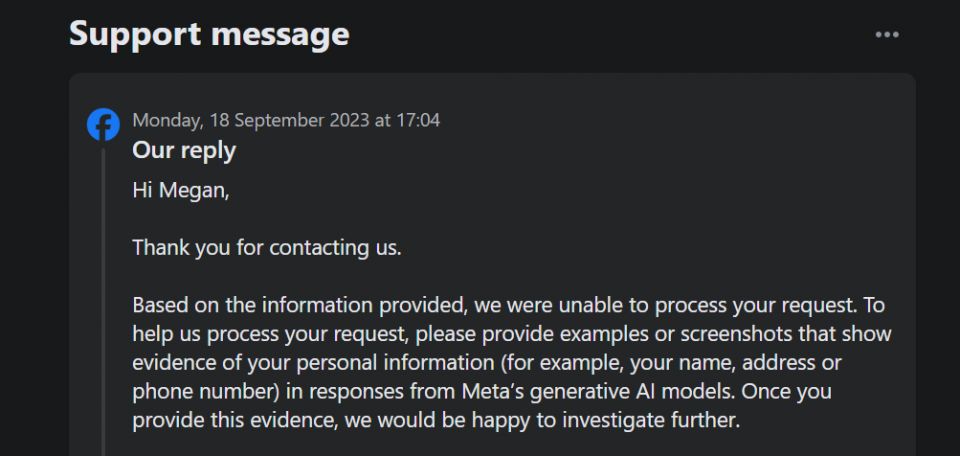
しかし、将来の処理に関しては、どうすればよいでしょうか?Metaは、生成データの主体権に関するフォームを導入しました。これにより、第三者がMetaの生成モデルをトレーニングするために個人データを処理することに異議を唱えたり、制限したりできます。
注目すべきは、このオプションでは、生成AIのトレーニングのためにMetaが独自のファーストパーティとしてデータを処理することに異議を唱えることはできないことです。さらに、フォームを使用して個人データの使用に異議を唱えるためのチケットを送信したとき、サポートチケットでは、私の個人情報がすでにMetaの生成結果に表示されていることを証明する必要がありました。
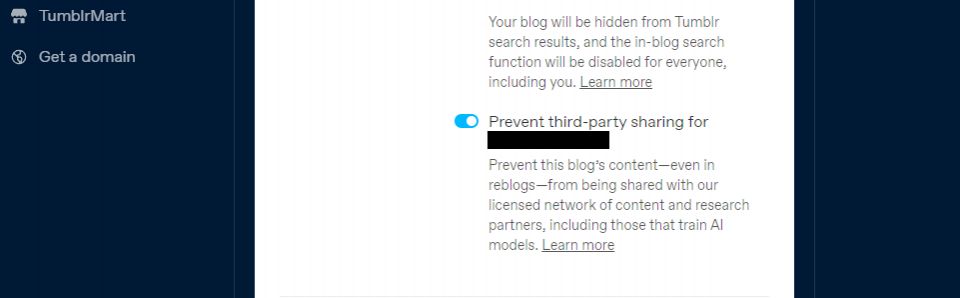
Tumblrはまた、ブログの設定を使用して、公開ブログのコンテンツを第三者と共有しないようにするオプションを導入しました。ブログをクリックして下にスクロールし、表示設定で確認できます。次に、ブログの第三者による共有を防止するを選択します。
Instagramなどのプラットフォームでは、データの使用を防ぐためにInstagramアカウントをプライベートに切り替えることができます。これによりデータが使用されなくなるという保証はありませんが、LLMのデータスクレイピングは公開データに焦点を当てているため、潜在的な安全策になる可能性があります。
X(Twitter)アカウントをプライベートにすることもできますが、これもあくまで潜在的な安全策であり、データが確実にプライベートに保たれるという保証はありません。
世界中のさまざまな国の情報担当委員や専門家による共同声明では、企業によるデータスクレイピングのプライバシーリスクを最小限に抑えたい個人向けのいくつかの対策が提案されています。アドバイスには以下が含まれます。
- ウェブサイトの利用規約とプライバシーポリシーを読んで、個人情報をどのように共有しているかを確認します。
- オンラインに投稿する情報を制限します。特に機密情報には注意します。
- プライバシー設定を管理します。
- オンラインで共有する情報について長期的に考えます。
- データが不適切にスクレイピングされたと思われる場合は、ソーシャルメディア企業またはウェブサイトに連絡します。彼らの対応に不満がある場合は、関連するデータ保護当局に苦情を申し立てます。
また、第三者がアクセスすることに抵抗がある場合は、オンラインで特定の情報を削除することもできますが、プロフィール上の公開情報はすでにスクレイピングされている可能性があります。
残念ながら、一般ユーザーとして企業からデータを保護するためにできることは限られています。この情報を実際に管理するには、規制当局の支援が必要になる可能性があります。
コメントする