データはさまざまな形や形式がありますが、重複レコードはあらゆるデータ形式の重要な部分です。Webベースのデータを扱っている場合でも、大量の販売データを単にナビゲートしている場合でも、重複値がある場合は分析が歪みます。
SQLを使用して数字を計算し、データスタックに対して長いクエリを実行していますか? その場合、このSQL重複の管理に関するガイドは、あなたにとって絶対的な喜びとなるでしょう。
SQLを使用して重複を管理するために使用できる方法はいくつかあります。
1. Group by関数を使用して重複をカウントする
SQLは、計算を簡素化するためのさまざまな関数を提供する多面的なプログラミング言語です。SQLの集計関数について十分な経験がある場合は、group by関数とその用途についてすでに知っているかもしれません。
group by関数は、最も基本的なSQLコマンドの1つであり、sum、count、averageなどのさまざまな集計関数と組み合わせて使用できるため、複数のレコードを扱うのに最適です。group by関数で、行ごとの値を取得します。
シナリオによっては、group by関数を使用して1つの列と複数の列内の重複を見つけることができます。
a. 1つの列の重複をカウントする
ProductIDとOrdersの2つの列を含む次のデータテーブルがあるとします。
ProductID | Orders |
2 | 7 |
2 | 8 |
2 | 10 |
9 | 6 |
10 | 1 |
10 | 5 |
12 | 5 |
12 | 12 |
12 | 7 |
14 | 1 |
14 | 1 |
47 | 4 |
47 | 4 |
重複したProductIDを見つけるには、group by関数とhaving句を使用して集計値をフィルタリングできます。次のようにします。
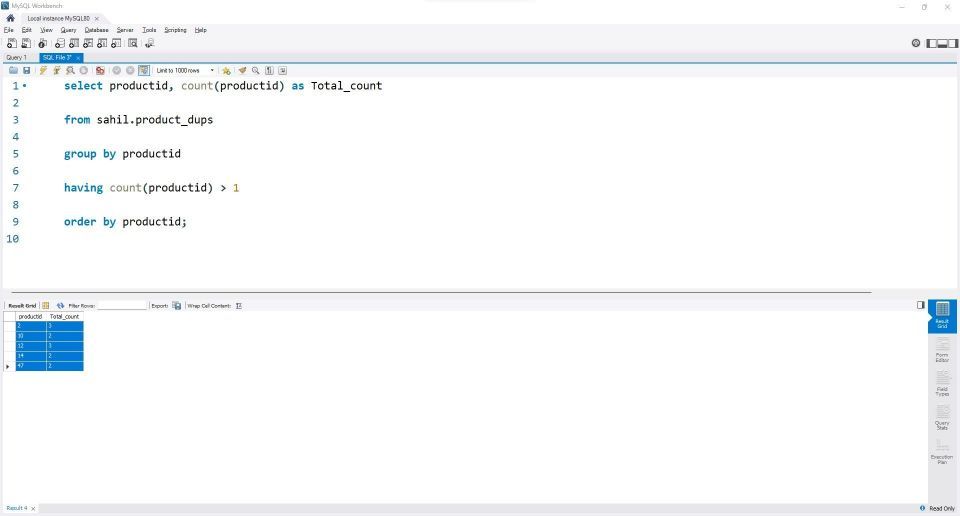
select productid, count(productid) as Total_count from sahil.product_dups group by productid having count(productid) > 1 order by productid;
通常のSQLステートメントと同様に、まず最終的な結果に表示する列を定義する必要があります。この場合、ProductID列内の重複値の数を表示します。
最初のセグメントでは、selectステートメント内でProductID列を定義します。count関数はProductID参照に従うため、SQLはクエリを理解します。
次に、from句を使用してソーステーブルを定義します。countは集計関数であるため、group by関数を使用してすべての類似した値をグループ化する必要があります。
重複値をProductID列にリストすることが目的であることに注意してください。そのためには、カウントをフィルタリングして、列に2回以上発生する値を表示する必要があります。having句は集計データをフィルタリングします。条件を使用できます(つまり、count(productid) >1)目的の結果を表示します。
最後に、order by句は最終的な結果を昇順にソートします。
出力は次のとおりです。
b. 複数の列で重複をカウントする
複数の列で重複をカウントしたいが、複数のSQLクエリを記述したくない場合は、上記コードを少し調整して拡張できます。たとえば、複数の列で重複行を表示するには、次のコードを使用できます。
select productid, orders, count(*) as Total_count from sahil.product_dups group by productid, orders having count(productid) > 1 order by productid;
出力では、2行のみが表示されることに注意してください。クエリを調整してselectステートメント内に両方の列の参照を追加すると、重複値を持つ一致行のカウントが得られます。
count(column)関数ではなく、count(*)関数を渡して重複行を取得する必要があります。*関数は個々の重複値ではなく、すべての行を切り替え、重複行を検索します。
出力を以下に示します。
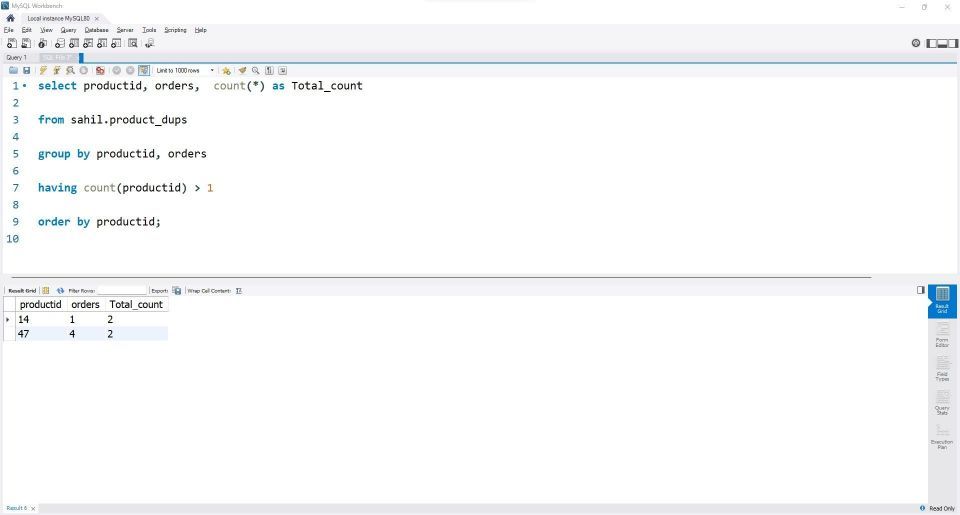
ProductID 14と47の対応する行が表示されます。これは、注文値が同じであるためです。
2. row_number()関数を使用して重複にフラグを立てる
group byとhavingの組み合わせは、テーブル内の重複を見つけてフラグを立てる最も簡単な方法ですが、row_number()関数を使用して重複を見つける別の方法があります。row_number()関数はSQLウィンドウ関数のカテゴリの一部であり、クエリを効率的に処理するために不可欠です。
row_number()関数を使用して重複にフラグを立てる方法を次に示します。
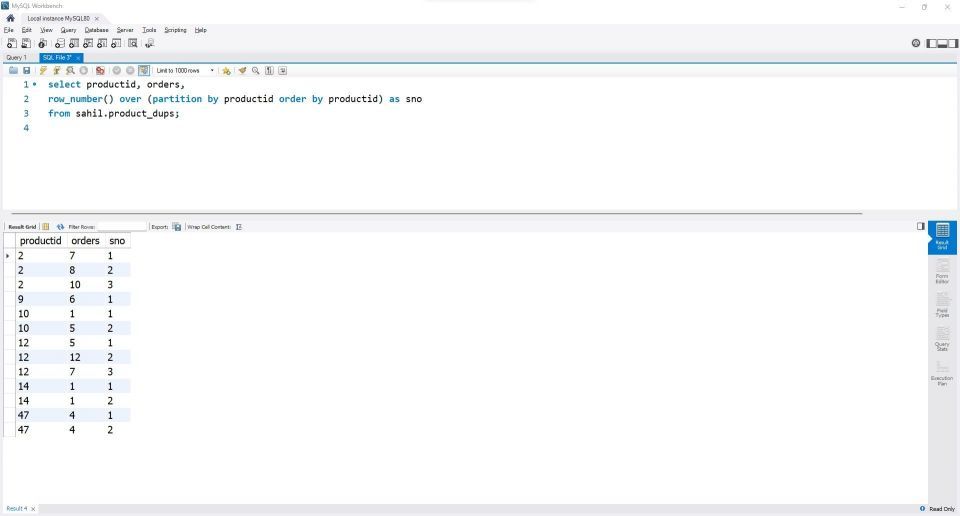
select productid, orders, row_number() over (partition by productid order by productid) as sno from sahil.product_dups;
row_number()関数は、各ProductID値を梳き通して、各IDの再発回数を同化します。partitionキーワードは重複値を分離し、1、2、3などのように値を時系列で割り当てます。
partitionキーワードを使用しない場合、すべてのProductIDの一意のシリアル番号が割り当てられますが、これは目的に合いません。
パーティションセクション内のorder by句は、ソート順を定義するときに機能します。昇順(デフォルト)と降順から選択できます。
最後に、後で(必要に応じて)フィルタリングしやすくするために、列にエイリアスを割り当てることができます。
3. SQLテーブルから重複行を削除する
テーブル内の重複値は分析を歪める可能性があるため、データクリーニングの段階で排除することが不可欠です。SQLは、重複値を追跡して効率的に削除する方法を提供する貴重な言語です。
a. distinctキーワードを使用する
distinctキーワードはおそらく、テーブル内の重複値を削除するための最も一般的でよく使用されるSQL関数です。1つの列から重複を削除したり、一度に重複行を削除したりできます。
1つの列から重複を削除する方法を次に示します。
select distinct productid from sahil.product_dups;
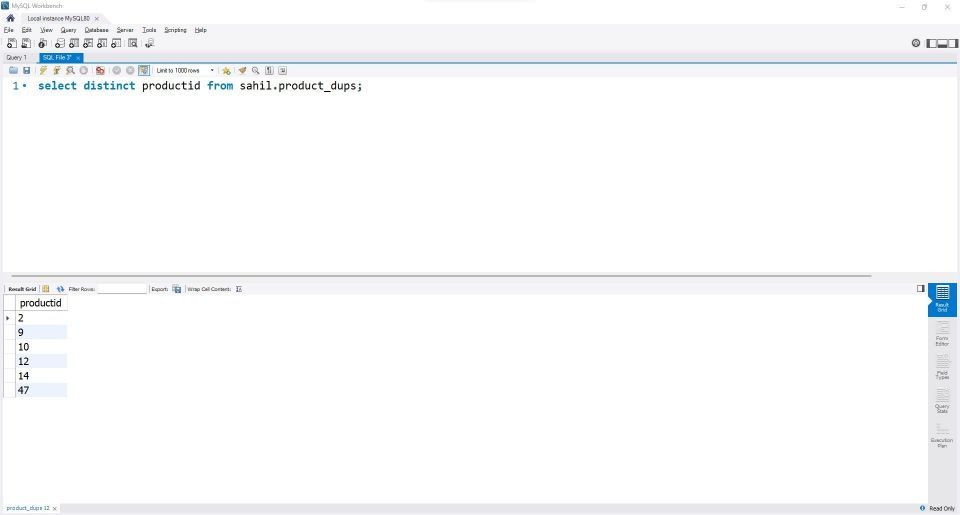
出力は、テーブルからすべてのユニークなProductIDのリストを返します。
重複行を削除するには、上記のコードを次のように調整できます。
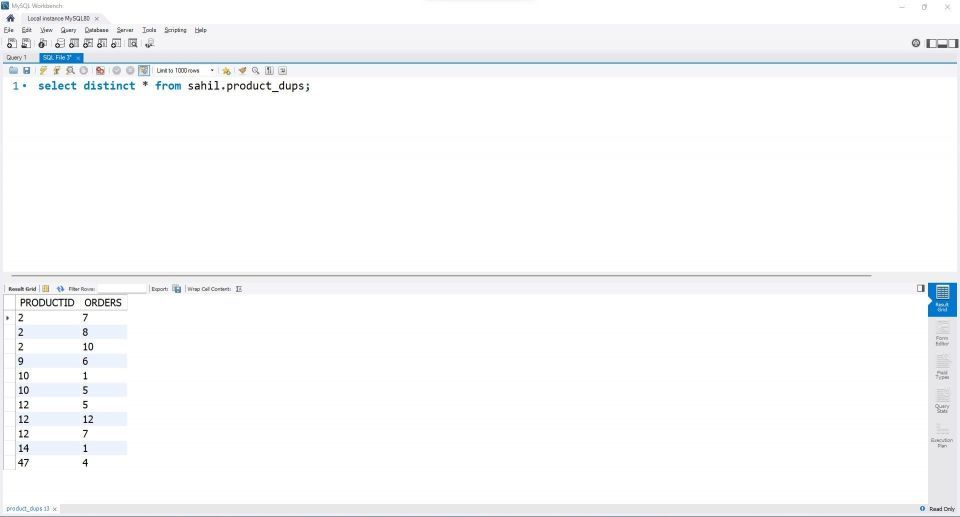
select distinct * from sahil.product_dups;
出力は、テーブルからすべてのユニークな行のリストを返します。出力を確認すると、ProductID 14と47が最終的な結果テーブルに1回だけ表示されていることがわかります。
b. 共通表式(CTE)メソッドを使用する
共通表式(CTE)メソッドは、主流のSQLコードとは少し異なります。CTEはSQLの一時テーブルに似ていますが、唯一の違いは仮想であることであり、クエリの実行中のみ参照できます。
最大の利点は、クエリを実行するとすぐにこれらのテーブルが消滅するため、後でこれらのテーブルを削除するための別のクエリを渡す必要がないことです。CTEメソッドを使用すると、以下のコードを使用して重複を見つけて削除できます。
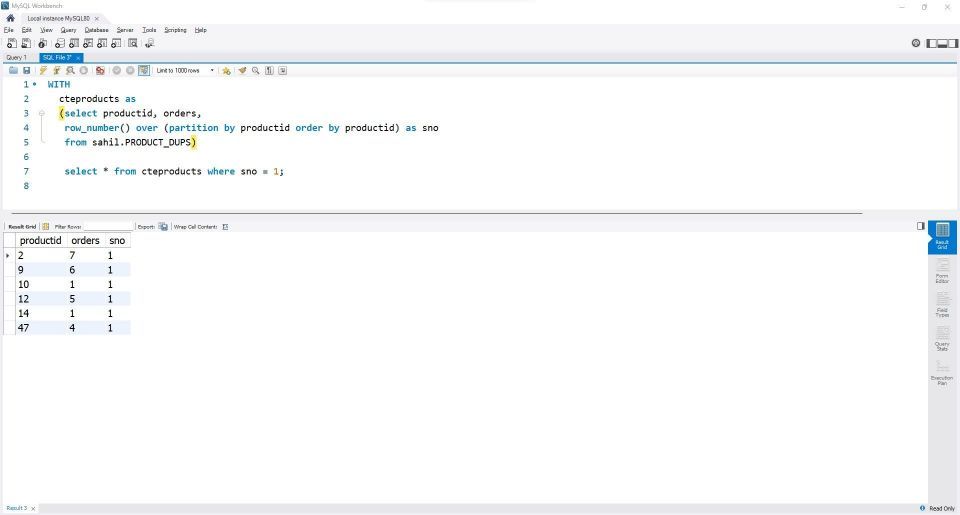
with cteproducts as (select productid, orders, row_number() over (partition by productid order by productid) as sno from sahil.product_dups) select * from cteproducts where sno = 1;
withキーワードを使用してCTE関数を呼び出すことができます。withキーワードの後に一時仮想テーブルの名前を定義します。CTEテーブル参照は、テーブルの値をフィルタリングする際に役立ちます。
次の部分で、row_number()関数を使用してProductIDに行番号を割り当てます。partition関数を使用して各ProductIDを参照しているため、各繰り返しIDには異なる値があります。
最後に、最後のセグメントで新しく作成されたsno列を別のselectステートメントでフィルタリングします。このフィルタを1に設定して、最終出力に一意の値を取得します。
SQLを簡単に学ぶ
SQLとそのバリエーションは、リレーショナルデータベースを照会および使用する生来の能力を備えているため、話題になっています。単純なクエリを記述することから、サブクエリによる精巧な分析を実行することまで、この言語にはすべてが少しあります。
ただし、クエリを記述する前に、スキルを磨き、コードを解読して熟練したコーダーになる必要があります。ゲームで知識を実装することで、楽しくSQLを学ぶことができます。コードに少し楽しみを加えて、おしゃれなコーディングのニュアンスを学びましょう。
コメントする