このデータ主導の意思決定の時代にあって、高品質のデータセットを持つことは不可欠です。一般に公開されているデータセットは数多くありますが、場合によっては、特定のニーズを満たすカスタムデータセットを作成する必要があるかもしれません。ウェブスクレイピングを使用すると、ウェブサイトからデータを抽出できます。その後、このデータを使用してカスタムデータセットを作成できます。
データ収集方法の概要
データ収集方法はさまざまです。手動データ入力、API、パブリックデータセット、ウェブスクレイピングなどが挙げられます。各手法には長所と短所があります。
手動データ入力は時間がかかり、特に大規模なデータ収集では人為的なミスが発生しやすいです。しかし、小規模なデータ収集や、他の手段ではデータを入手できない場合に役立ちます。
APIを使用すると、開発者は構造化された方法でデータにアクセスして取得することができます。これらは、多くの場合、リアルタイムまたは定期的に更新される情報を提供します。ただし、APIアクセスは制限されている場合があり、認証が必要であったり、使用制限がある場合があります。
パブリックデータセットは、幅広いトピックやドメインを網羅しています。これらは事前に収集されており、多くの場合、構造化された形式で提供されているため、簡単にアクセスできます。必要なデータが入手可能なデータセットと一致している場合、時間と労力を節約できます。ただし、常に特定のニーズをカバーしているわけではなく、最新ではない場合があります。
ウェブスクレイピングは、APIを提供していない、またはアクセスが制限されているウェブサイトからデータを収集する方法を提供します。カスタマイズ、スケーラビリティ、複数のソースからデータを収集する機能が備わっています。ただし、プログラミングスキル、HTML構造の知識、法的および倫理的ガイドラインへの遵守が必要です。
データ収集のためのウェブスクレイピングの選択
ウェブスクレイピングを使用すると、ウェブページから直接情報を抽出できるため、幅広いデータソースにアクセスできます。また、抽出するデータと構造化する方法を制御できます。これにより、スクレイピングプロセスを特定の要件に合わせて調整し、プロジェクトに必要な正確な情報を抽出することが容易になります。
データソースの特定
ウェブスクレイピングの最初のステップは、データソースを特定することです。これは、スクレイピングしたいデータを含むウェブサイトです。データソースを選択する際には、ソースの利用規約に準拠していることを確認してください。この記事では、IMDb(インターネットムービーデータベース)をデータソースとして使用します。
環境の設定
仮想環境を設定します。次に、次のコマンドを実行して必要なライブラリをインストールします。
pip install requests beautifulsoup4 pandas
requestsライブラリを使用してHTTPリクエストを行います。beautifulsoup4を使用してHTMLコンテンツを解析し、ウェブページからデータを取得します。最後に、pandasを使用してデータを操作および分析します。
完全なソースコードはGitHubリポジトリで入手できます。
ウェブスクレイピングスクリプトの記述
スクリプトにインストールしたライブラリをインポートして、それらが提供する関数を使用できるようにします。
import requests from bs4 import BeautifulSoup import time import pandas as pd import re
timeとreモジュールはPython標準ライブラリの一部です。したがって、別のインストールは必要ありません。
timeはスクレイピングプロセスに遅延を追加し、reは正規表現を扱います。
Beautiful Soupを使用してターゲットウェブサイトをスクレイピングします。
ターゲットURLにHTTP GETリクエストを送信する関数を作成します。次に、応答のコンテンツを取得し、HTMLコンテンツからBeautifulSoupオブジェクトを作成する必要があります。
def get_soup(url, params=None, headers=None): response = requests.get(url, params=params, headers=headers) soup = BeautifulSoup(response.content, "html.parser") return soup
次のステップは、BeautifulSoupオブジェクトから情報を抽出することです。
必要な情報を抽出するには、ターゲットウェブサイトの構造を理解する必要があります。これには、ウェブサイトのHTMLコードを調べる必要があります。これにより、抽出するデータを含む要素と属性を特定するのに役立ちます。ターゲットウェブサイトを調べるには、ウェブブラウザでそのリンクを開き、スクレイピングするデータを含むウェブページに移動します。
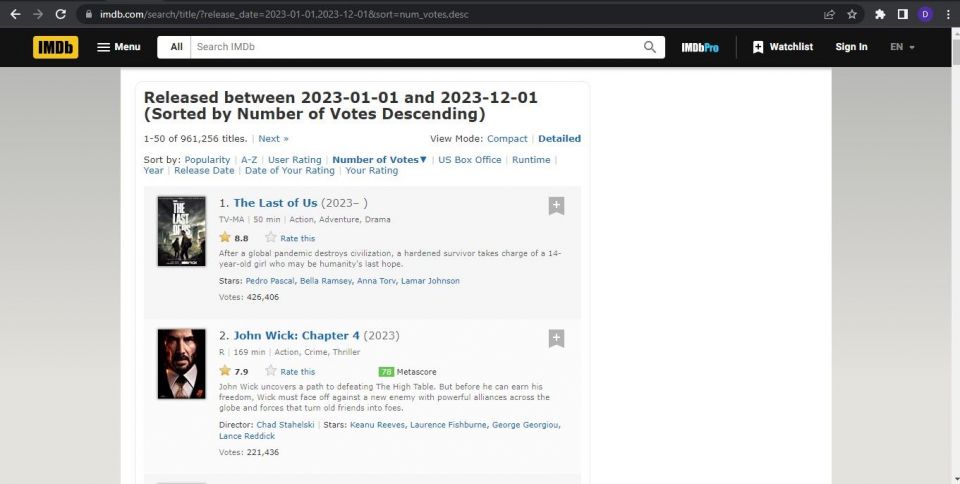
次に、ウェブページを右クリックしてコンテキストメニューから検査を選択します。これにより、ブラウザの開発者ツールが開きます。
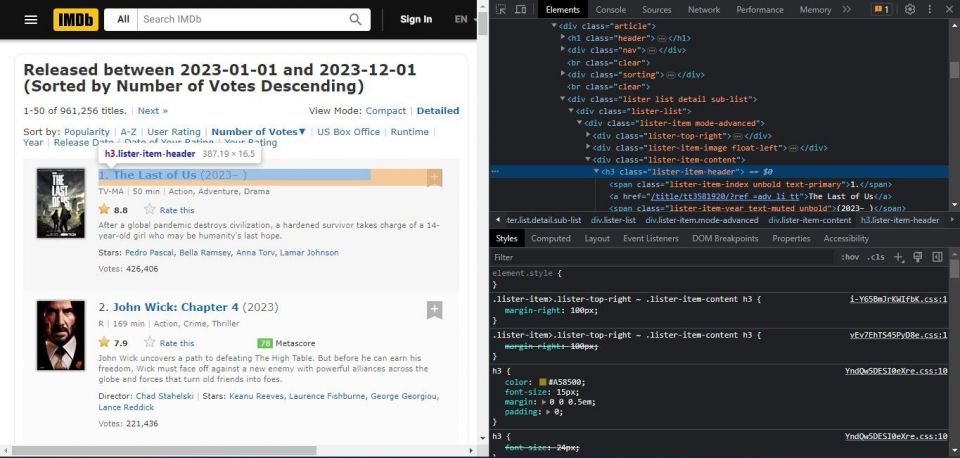
ウェブページのHTMLコードで、スクレイピングするデータを含む要素を探します。必要なデータに関連付けられているHTMLタグ、クラス、属性に注意してください。BeautifulSoupを使用してデータを抽出するためのセレクタを作成するためにそれらを使用します。上記のスクリーンショットでは、映画のタイトルがlister-item-headerクラス内にあることがわかります。抽出する各機能を調べます。
BeautifulSoupオブジェクトから情報を抽出する関数を作成します。この場合、この関数は、適切なHTMLタグとクラス属性を使用して、映画のタイトル、評価、説明、ジャンル、公開日、監督、スターを見つけます。
def extract_movie_data(movie):
title = movie.find("h3", class_="lister-item-header").find("a").text
rating = movie.find("div", class_="ratings-imdb-rating").strong.text
description = movie.find("div", class_="lister-item-content").find_all("p")[1].text.strip()
genre_element = movie.find("span", class_="genre")
genre = genre_element.text.strip() if genre_element else None
release_date = movie.find("span", class_="lister-item-year text-muted unbold").text.strip()
director_stars = movie.find("p", class_="text-muted").find_all("a")
directors = [person.text for person in director_stars[:-1]]
stars = [person.text for person in director_stars[-1:]]
movie_data = {
"タイトル": title,
"評価": rating,
"説明": description,
"ジャンル": genre,
"公開日": release_date,
"監督": directors,
"スター": stars
}
return movie_data
最後に、上記の2つの関数を使用して実際のスクレイピングを行う関数を作成します。スクレイピングする年と映画の最大数を指定します。
def scrape_imdb_movies(year, limit):
base_url = "https://www.imdb.com/search/title"
headers = {"Accept-Language": "en-US,en;q=0.9"}
movies = []
start = 1
while len(movies) < limit:
params = {
"release_date": year,
"sort": "num_votes,desc",
"start": start
}
soup = get_soup(base_url, params=params, headers=headers)
movie_list = soup.find_all("div", class_="lister-item mode-advanced")
if len(movie_list) == 0:
break
for movie in movie_list:
movie_data = extract_movie_data(movie)
movies.append(movie_data)
if len(movies) >= limit:
break
start += 50 # IMDbは1ページに50本の映画を表示します
time.sleep(1) # サーバーに負荷をかけすぎないように遅延を追加します
return movies
次に、def scrape_imdb_moviesを呼び出してスクレイピングを行います。
# 2023年に公開された1000本の映画をスクレイピングします(または可能な限り多く) movies = scrape_imdb_movies(2023, 1000)
これでデータをスクレイピングしました。
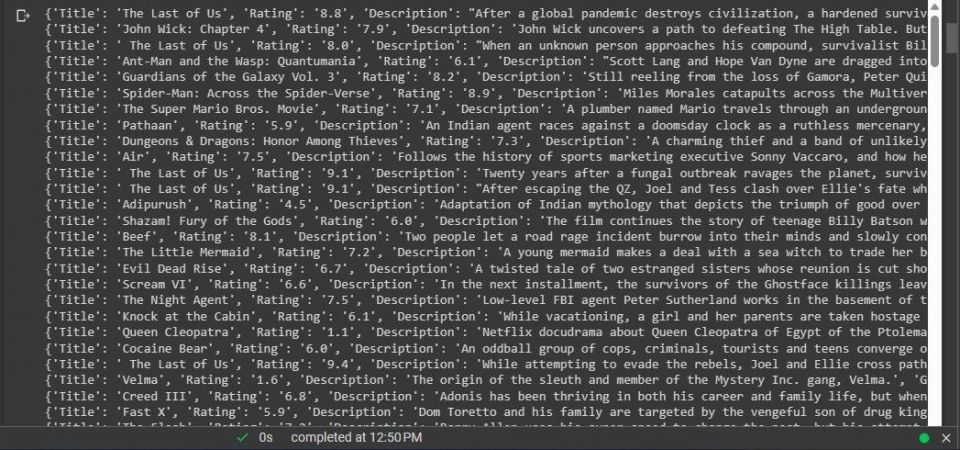
次のステップは、このデータからデータセットを作成することです。
スクレイピングしたデータからデータセットを作成する
スクレイピングしたデータからPandasを使用してDataFrameを作成します。
df = pd.DataFrame(movies)
次に、データの前処理とクリーニングを行います。この場合、欠損値のある行を削除します。次に、公開日から年を抽出し、数値に変換します。不要な列を削除します。Rating列を数値に変換します。最後に、Title列から非アルファベット文字を削除します。
df = df.dropna()
df['公開年'] = df['公開日'].str.extract(r'(\d{4})')
df['公開年'] = pd.to_numeric(df['公開年'],
errors='coerce').astype('Int64')
df = df.drop(['公開日'], axis=1)
df['評価'] = pd.to_numeric(df['評価'], errors='coerce')
df['タイトル'] = df['タイトル'].apply(lambda x: re.sub(r'\W+', ' ', x))
後でプロジェクトで使用できるように、データをファイルに保存します。
df.to_csv("imdb_movies_dataset.csv", index=False)
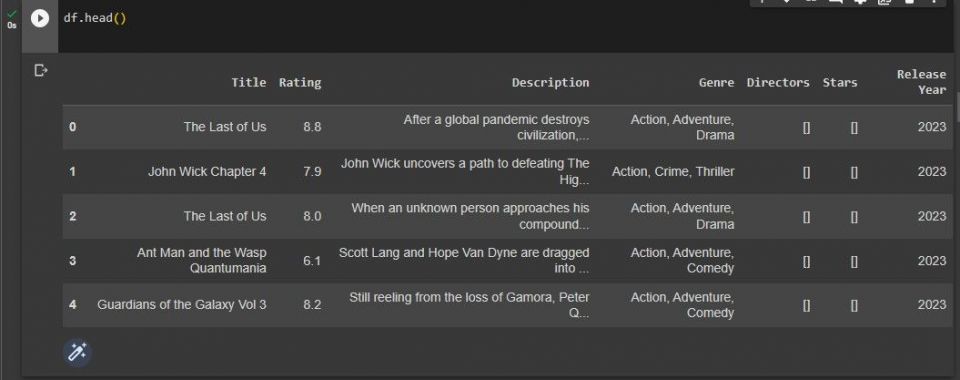
最後に、データセットの最初の5行を出力して、どのように見えるかを確認します。
df.head()
出力は次のスクリーンショットに示すようになります。
これで、ウェブスクレイピングによって取得されたデータセットができました。
他のPythonライブラリを使用したウェブスクレイピング
Beautiful Soupは、ウェブスクレイピングに使用できるPythonライブラリではありません。他にもさまざまなライブラリがあります。それぞれに長所と短所があります。使用例に最適なライブラリを見つけるために調査してください。
コメントする