- Linux の grep コマンドは、文字列とパターンの照合に役立つツールで、さまざまなオプションを使用してテキスト ファイルを検索できます。
- grep を使用すると、単純な検索、再帰的な検索、単語全体を検索、複数の検索語を使用、一致数をカウント、コンテキストの追加、さらに出力を他のコマンドにパイプしてさらに操作することができます。
Linux のgrepコマンドは、複数のファイルから一致する行を表示する文字列およびパターンの照合ユーティリティです。他のコマンドからのパイプ出力でも機能します。その方法を紹介します。
Linux の grep コマンド
grepコマンドは、Linux や Unix の世界で 3 つの理由から有名です。まず、非常に便利です。次に、オプションが豊富すぎて圧倒される可能性があります。最後に、特定のニーズを満たすために一晩で作成されました。最初の 2 つはぴったりですが、3 つ目は少し違います。
ケン・トンプソンは、edエディター (イーディーと発音) から正規表現検索機能を抽出し、自分のためにテキスト ファイルを検索する小さなプログラムを作成しました。ベル研究所の彼の部門長であるダグ・マキルロイがトンプソンに近づき、彼の同僚の 1 人であるリー・マクマホンが直面している問題について説明しました。
マクマホンは、テキスト分析を通じて連邦党文書の著者を特定しようとしていました。彼は、テキスト ファイル内でフレーズや文字列を検索できるツールを必要としていました。トンプソンはその夜、約 1 時間かけて自分のツールを他の人が使用できるようにする一般的なユーティリティにし、grepという名前を付けました。彼は、edコマンド文字列g/re/pからその名前を取りました。これは「グローバル正規表現検索」と解釈されます。
トンプソンがブライアン・カーニハンとgrepの誕生について話す様子を見ることができます。
grep コマンドを使用した単純な検索
ファイル内で文字列を検索するには、コマンド ラインで検索語とファイル名を指定します。

一致する行が表示されます。この場合、1 行です。一致するテキストが強調表示されます。これは、ほとんどのディストリビューションでgrepが次のエイリアスになっているためです。
alias grep='grep --colour=auto'
一致する行が複数ある結果を見てみましょう。アプリケーション ログ ファイルで「平均」という単語を探します。ログ ファイルに単語が小文字で含まれているかどうか思い出せないため、-i (大文字小文字を区別しない) オプションを使用します。
grep -i Average geek-1.log

一致する行がすべて表示され、それぞれの行で一致するテキストが強調表示されます。
-v (一致を反転) オプションを使用すると、一致しない行を表示できます。
grep -v Mem geek-1.log

これらは一致しない行なので、強調表示はありません。
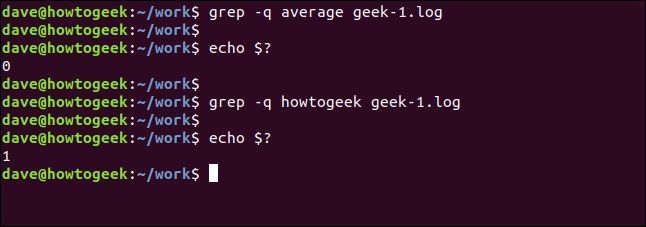
grepを完全にサイレントにすることができます。結果は、grepからの戻り値としてシェルに渡されます。ゼロの結果は文字列が見つかったことを意味し、1 の結果は見つからなかったことを意味します。$?特殊パラメータを使用して戻りコードを確認できます。
grep -q average geek-1.log
echo $?
grep -q howtogeek geek-1.log
echo $?
grep を使用した再帰的検索
入れ子になったディレクトリとサブディレクトリを検索するには、-r (再帰的) オプションを使用します。コマンド ラインでファイル名を指定しないことに注意してください。パスを指定する必要があります。ここでは、カレント ディレクトリ「.」とそのサブディレクトリを検索します。
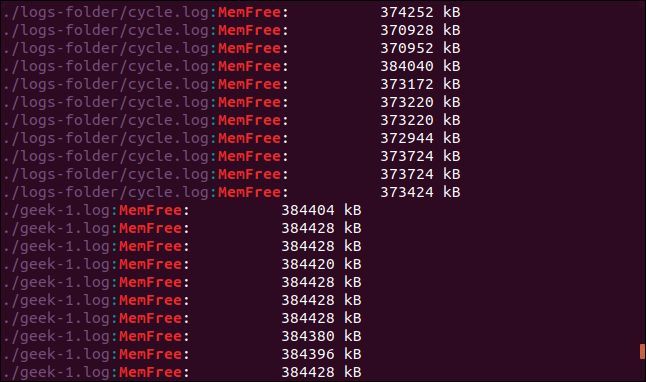
grep -r -i memfree .

出力には、一致する行のディレクトリとファイル名が含まれます。
-R (再帰的逆参照) オプションを使用すると、grepがシンボリック リンクをたどるようにすることができます。このディレクトリには、logs-folderというシンボリック リンクがあります。これは/home/dave/logsを指しています。
ls -l logs-folder

-R (再帰的逆参照) オプションを使用して、最後の検索を繰り返してみましょう。
grep -R -i memfree .

シンボリック リンクがたどられ、そのリンクが指すディレクトリもgrepによって検索されます。
grep コマンドを使用した単語全体の検索
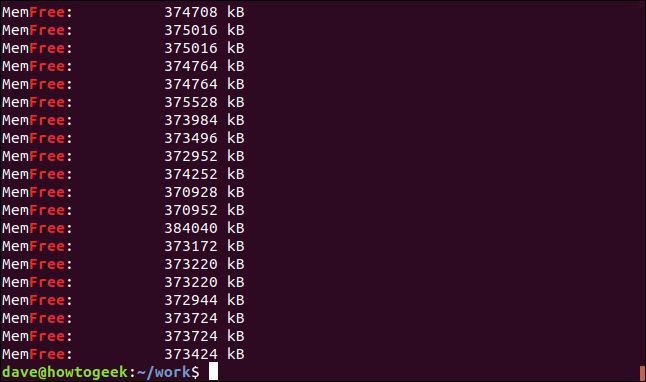
デフォルトでは、grepは検索対象が別の文字列内にある場合でも、その行のどこかに表示されれば行と一致します。この例を見てみましょう。「free」という単語を検索します。
grep -i free geek-1.log

結果は「free」という文字列を含む行ですが、別々の単語ではありません。「MemFree」という文字列の一部です。
grepを別々の「単語」のみと一致させるようにするには、-w (単語正規表現) オプションを使用します。
grep -w -i free geek-1.log
echo $?
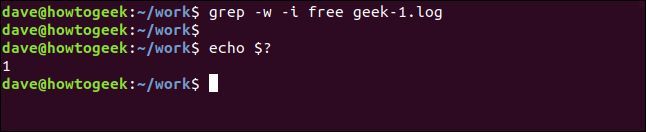
今回は、検索語「free」がファイルに別々の単語として表示されないため、結果はありません。
複数の検索語を使用する
-E (拡張正規表現) オプションを使用すると、複数の単語を検索できます。(-Eオプションは、grepの非推奨となったegrepバージョンに置き換わりました。)
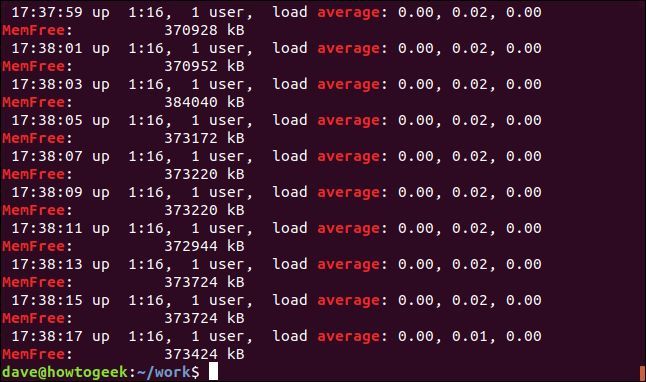
このコマンドは、「average」と「memfree」という 2 つの検索語を検索します。
grep -E -w -i "average|memfree" geek-1.log

一致する行はすべて、各検索語について表示されます。
必ずしも単語全体ではない複数の語を検索することもできますが、単語全体にすることもできます。
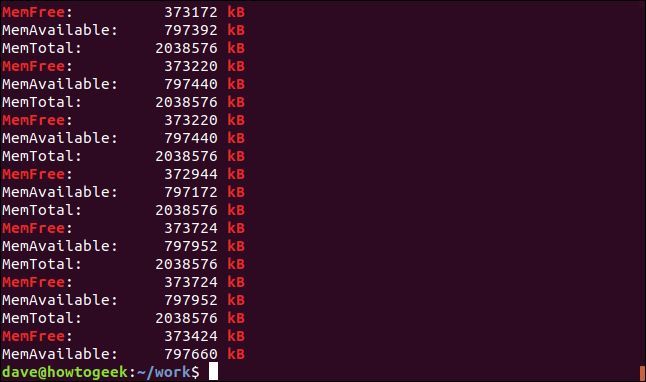
-e (パターン) オプションを使用すると、コマンド ラインで複数の検索語を使用できます。正規表現の括弧機能を使用して検索パターンを作成します。grepに「[]」内の任意の 1 文字と一致するように指示します。つまり、grepは検索中に「kB」または「KB」のいずれかと一致します。

両方の文字列が一致し、実際には、いくつかの行には両方の文字列が含まれています。
行を完全に一致させる
-x (行正規表現) は、行全体が検索語と一致する場合にのみ一致します。ログ ファイルに 1 回だけ表示される日付と時刻のスタンプを検索してみましょう。
grep -x "20-Jan--06 15:24:35" geek-1.log

一致する単一行が見つかり、表示されます。
その逆は、一致しない行のみを表示することです。これは、設定ファイルを見るときに便利です。コメントは便利ですが、その中に実際の設定を見つけるのは難しい場合があります。これが/etc/sudoersファイルです。
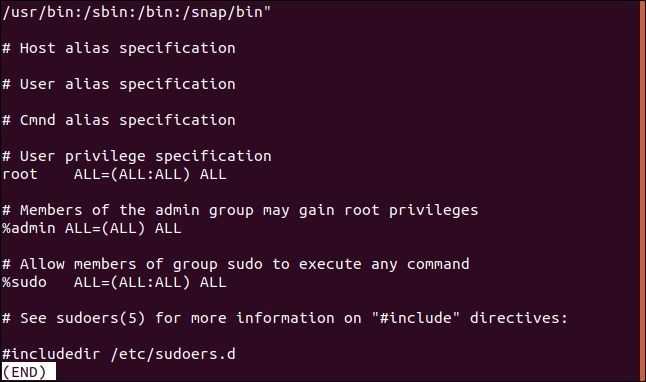
次のようにして、コメント行を効果的にフィルター処理できます。
sudo grep -v "#" /etc/sudoers
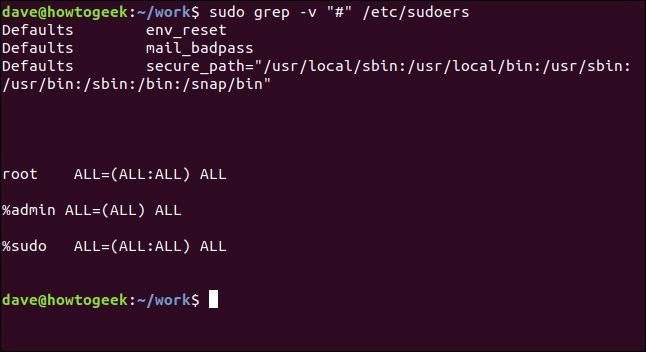
解析がはるかに簡単になりました。
一致するテキストのみを表示する
一致する行全体ではなく、一致するテキストのみを表示したい場合があります。-o (一致のみ) オプションはまさにそれを行います。
grep -o MemFree geek-1.log

一致する行全体ではなく、検索語と一致するテキストのみが表示されます。

grep を使用したカウント
grepはテキストだけを扱うのではなく、数値情報も提供できます。grepを使用してさまざまな方法でカウントできます。ファイル内で検索語が何回表示されるかを知りたい場合は、-c (カウント) オプションを使用できます。
grep -c average geek-1.log

grepは、検索語がこのファイルに 240 回表示されると報告します。
-n (行番号) オプションを使用すると、grepで一致する行ごとにその行番号を表示できます。
grep -n Jan geek-1.log

一致する行の行番号が各行の最初に表示されます。
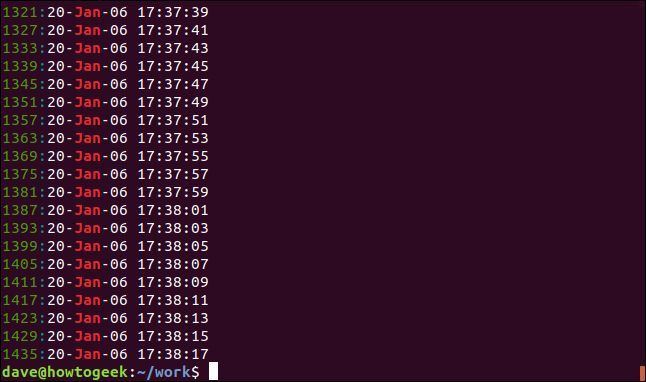
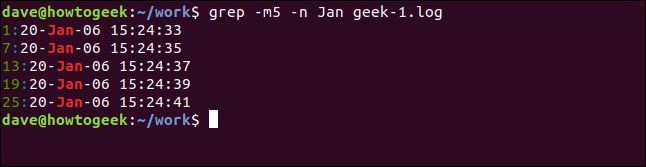
表示される結果の数を減らすには、-m (最大カウント数) オプションを使用します。出力を 5 つの一致する行に制限します。
grep -m5 -n Jan geek-1.log
grep を使用したコンテキストの追加
一致する行ごとに追加の行 (一致しない行の可能性あり) を表示できると、便利です。一致する行のうち、興味のある行を区別するのに役立ちます。
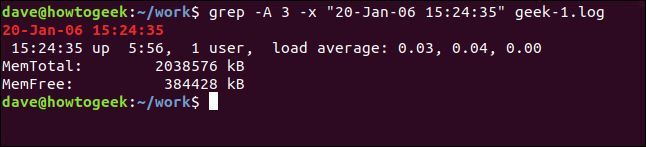
一致する行の後にいくつかの行を表示するには、-A (コンテキストの後) オプションを使用します。この例では 3 行を要求します。
grep -A 3 -x "20-Jan-06 15:24:35" geek-1.log
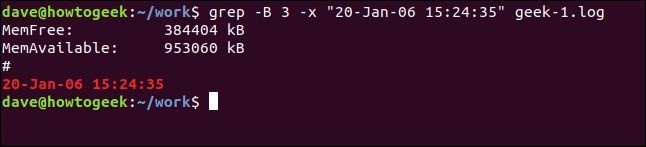
一致する行の前にいくつかの行を表示するには、-B (コンテキストの前) オプションを使用します。
grep -B 3 -x "20-Jan-06 15:24:35" geek-1.log
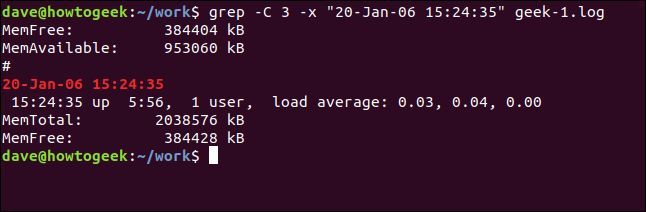
一致する行の前後の行を含めるには、-C (コンテキスト) オプションを使用します。
grep -C 3 -x "20-Jan-06 15:24:35" geek-1.log
一致するファイルの表示
検索語を含むファイルの名前を表示するには、-l (一致するファイル) オプションを使用します。sl.hヘッダー ファイルへの参照を含む C ソース コード ファイルを調べるには、次のコマンドを使用します。
grep -l "sl.h" *.c

一致する行ではなく、ファイル名が一覧表示されます。

もちろん、検索語を含まないファイルを探すこともできます。-L (一致しないファイル) オプションはまさにそれを行います。
grep -L "sl.h" *.c

行の始めと終わり
grepに、行の始めまたは終わりにある一致のみを表示するように強制することができます。正規表現演算子の「^」は行の始めと一致します。ログ ファイル内のほとんどの行にはスペースが含まれていますが、最初の文字がスペースである行を検索します。
grep "^ " geek-1.log

最初の文字がスペースである行 (行の始め) が表示されます。
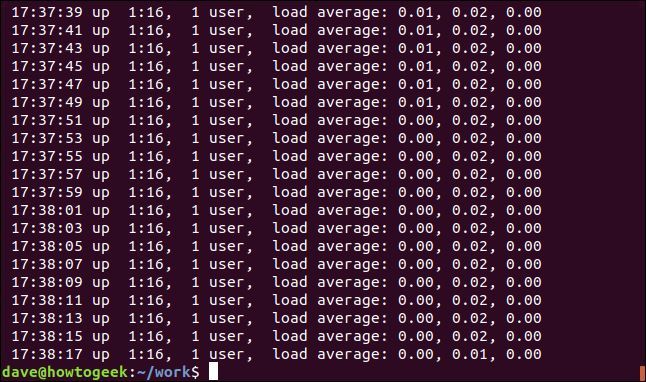
行の終わりと一致させるには、正規表現演算子「$」を使用します。「00」で終わる行を検索します。
grep "00$" geek-1.log

最後に「00」がある行が表示されます。
grep を使用したパイプ
もちろん、grepに入力をパイプしたり、grepからの出力を別のプログラムにパイプしたり、grepをパイプ チェーンの中間に配置したりできます。
lessにパイプします。
grep "ExtractParameters" *.c | less

出力がlessで表示されます。
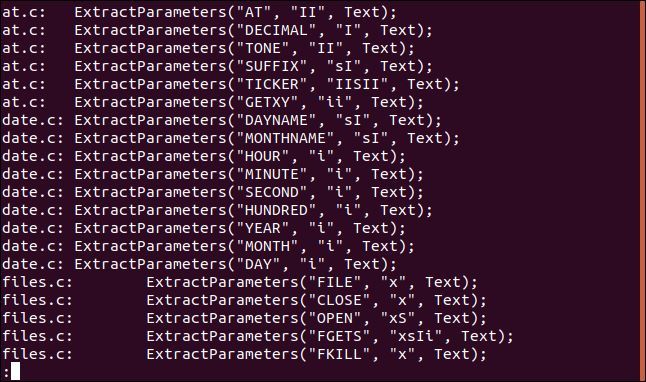
これにより、ファイル一覧をページングしてlessの検索機能を使用できます。
grepからの出力をwcにパイプし、-l (行) オプションを使用すると、ソース コード ファイル内で「ExtractParameters」が含まれている行の数をカウントできます。(grepの-c (カウント) オプションを使用してこれを実現することもできますが、これはgrepからのパイプの出し方を示すのに優れた方法です。)
grep "ExtractParameters" *.c | wc -l

次のコマンドでは、lsからの出力をgrepにパイプし、grepからの出力をsortにパイプしています。カレント ディレクトリ内のファイルを一覧表示し、「Aug」という文字列が含まれているファイルを選択し、ファイル サイズでソートします。
ls -l | grep "Aug" | sort +4n
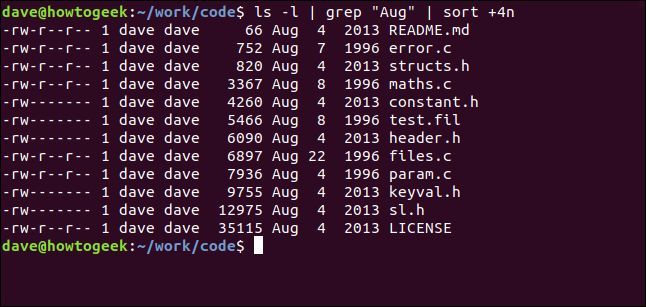
分解してみましょう。
- ls -l:
lsを使用して、ファイルの長い形式の一覧を実行します。 - grep "Aug":
ls一覧から「Aug」が含まれている行を選択します。これにより、名前に「Aug」が含まれているファイルも見つかります。 - sort +4n: grep からの出力を 4 番目の列 (ファイルサイズ) でソートします。
年を問わず 8 月に変更されたすべてのファイルのソートされた一覧が、ファイル サイズの昇順で得られます。
Linux の grep: コマンドというより、仲間
grepは、手元に置いておくのに最適なツールです。1974 年にさかのぼり、今でも強力であり続けています。その機能が必要であり、それ以上の機能を提供するものはありません。
grepを正規表現と組み合わせると、本当に次のレベルに引き上げることができます。
コメントする