- Linux の cut コマンドは、ファイルやデータストリームからテキストの一部を抽出できます。
- cut はバイト、文字、区切られたフィールドを操作できるので、条件に基づいてテキストの特定の部分を選択できます。
- cut は、grep などの他のユーティリティと組み合わせて、より複雑な操作を実行できます。
Linux のcutコマンドは、ファイルやデータストリームからテキストの一部を抽出できます。区切られたデータ(CSV ファイルなど)を操作するのに特に便利です。知っておくべき内容を説明します。
cut コマンド
cutコマンドは Unix の世界ではベテランで、1982 年に AT&T System III UNIX の一部としてデビューしました。その目的は、指定した条件に従って、ファイルやストリームからテキストの一部を切り取ることです。その構文は目的と同じくらいシンプルですが、そのシンプルな組み合わせが非常に便利なのです。
UNIX の伝統的な方法で、cutをgrepなどの他のユーティリティと組み合わせると、困難な問題を解決するためのエレガントで強力なソリューションを作成できます。cutにはさまざまなバージョンがありますが、標準的な GNU/Linux バージョンについて説明します。BSD バリアントにあるcutなど、他のバージョンにはここで説明するすべてのオプションが含まれていないことに注意してください。
次のコマンドを実行して、コンピュータにインストールされているバージョンを確認できます。
cut --version
出力に「GNU coreutils」と表示されている場合、この記事で説明するバージョンを使用しています。cutのすべてのバージョンにはこの機能の一部がありますが、Linux バージョンには機能強化が追加されています。
cut の最初のステップ
cutに情報をパイプするか、cutを使用してファイルを読み取るかに関係なく、使用するコマンドは同じです。cutを使用して入力ストリームに対して実行できることはすべて、ファイルのテキスト行に対して実行できます。その逆も同様です。cutにバイト、文字、区切られたフィールドのいずれかで操作するように指示できます。
1 つのバイトを選択するには、-b(バイト)オプションを使用して、cutに目的のバイトを指定します。この場合、5 番目のバイトです。echoからパイプ「|」を使用して文字列「how-to geek」をcutコマンドに送信しています。
echo 'how-to geek' | cut -b 5

その文字列の 5 番目のバイトは「t」なので、cutはターミナルウィンドウに「t」を印刷して応答します。
範囲を指定するには、ハイフンを使用します。5 番目のバイトから 11 番目のバイトまで(11 番目のバイトを含む)を抽出するには、次のコマンドを実行します。
echo 'how-to geek' | cut -b 5-11

複数の単一バイトまたは範囲をカンマで区切って指定できます。5 番目のバイトと 11 番目のバイトを抽出するには、次のコマンドを使用します。
echo 'how-to geek' | cut -b 5,11

各単語の最初の文字を取得するには、次のコマンドを使用できます。
echo 'how-to geek' | cut -b 1,5,8

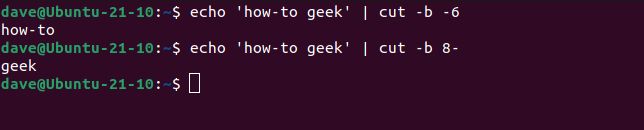
最初の数字なしでハイフンを使用すると、cutは 1 番目の位置から数字までのすべてを返します。2 番目の数字なしでハイフンを使用すると、cutは最初の数字からストリームまたは行の最後まですべてを返します。
echo 'how-to geek' | cut -b -6
echo 'how-to geek' | cut -b 8-
文字で cut を使用する
cutを文字で使用する方法は、バイトで使用するのとほぼ同じです。どちらの場合でも、複雑な文字には特に注意する必要があります。-c(文字)オプションを使用すると、cutにバイトではなく文字で操作するように指示できます。
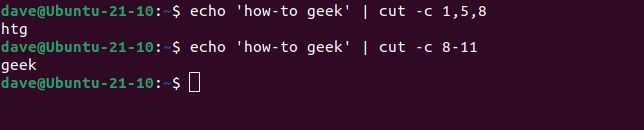
echo 'how-to geek' | cut -c 1,5,8
echo 'how-to geek' | cut -c 8-11
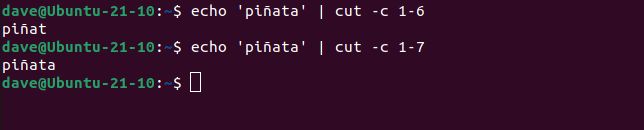
これらはすべて、期待どおりに機能します。しかし、この例を見てみましょう。これは 6 文字の単語なので、cutに 1 から 6 までの文字を返すように指示すると、単語全体が返されるはずです。しかし、そうではありません。1 文字足りません。単語全体を見るには、1 から 7 までの文字を要求する必要があります。
echo 'piñata' | cut -c 1-6
echo 'piñata' | cut -c 1-7
問題は、「ñ」という文字が実際には 2 つのバイトから構成されていることです。これは簡単に確認できます。このテキスト行を含む短いテキストファイルがあります。
cat unicode.txt

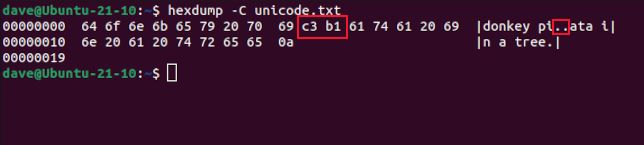
hexdumpユーティリティでそのファイルを確認します。-C(正規)オプションを使用すると、右側に ASCII の同等文字がある 16 進数字の表が表示されます。ASCII 表では「ñ」は表示されず、代わりに 2 つの非印刷文字を表すドットが表示されます。これらは 16 進数表でハイライトされているバイトです。
hexdump -C unicode.txt
これらの 2 つのバイトは、「ñ」を識別するために、この場合 Bash シェルである表示プログラムによって使用されます。多くの Unicode 文字は、3 つ以上のバイトを使用して 1 文字を表します。
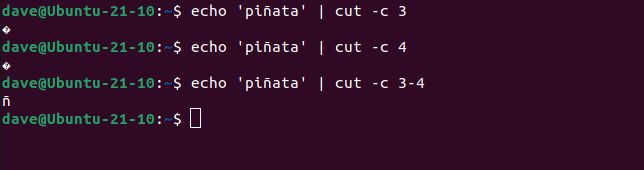
文字 3 または文字 4 を要求すると、非印刷文字のシンボルが表示されます。バイト 3 と 4 を要求すると、シェルはそれらを「ñ」として解釈します。
echo 'piñata' | cut -c 3
echo 'piñata' | cut -c 4
echo 'piñata' | cut -c 3-4
区切られたデータで cut を使用する
指定した区切り文字を使用して、cutにテキスト行を分割するように指示できます。デフォルトでは、cut はタブ文字を使用しますが、必要なものを何でも使用するように指示するのは簡単です。"/etc/passwd" ファイルのフィールドはコロン「:」で区切られているので、それを区切り文字として使用してテキストを抽出します。
区切り文字の間のテキストの部分はフィールドと呼ばれ、バイトや文字と同様に参照されますが、-f(フィールド)オプションが前に付けられます。「f」と数字の間にスペースを挿入することも、挿入しないこともできます。
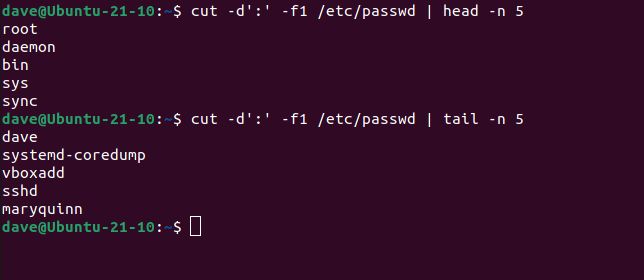
最初のコマンドは、-d(区切り文字)オプションを使用して、cut に「:」を区切り文字として使用するように指示します。"/etc/passwd" ファイルの各行から最初のフィールドを取得します。それは長いリストになるので、headと-n(number)オプションを使用して、最初の 5 つの応答のみを表示します。2 番目のコマンドは同じことを行いますが、tailを使用して最後の 5 つの応答を表示します。
cut -d':' -f1 /etc/passwd | head -n 5
cut -d':' -f2 /etc/passwd | tail -n 5
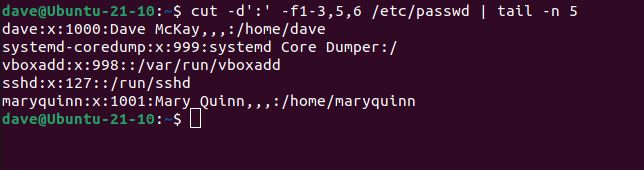
フィールドの選択を抽出するには、それらをコンマ区切りのリストとして一覧表示します。このコマンドは、フィールド 1 から 3、5、6 を抽出します。
cut -d':' -f1-3,5,6 /etc/passwd | tail -n 5
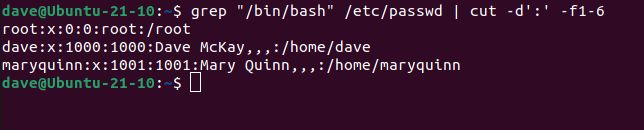
コマンドにgrepを含めることで、"/bin/bash" を含む行を検索できます。つまり、デフォルトのシェルとして Bash を持つエントリのみを一覧表示できます。通常は「通常の」ユーザーアカウントになります。7 番目のフィールドがデフォルトのシェルフィールドで、それが何であるかはすでにわかっているので、1 から 6 のフィールドを要求します。
grep "/bin/bash" /etc/passwd | cut -d':' -f1-6
1 つのフィールドを除くすべてのフィールドを含める別の方法は、--complementオプションを使用することです。これにより、フィールドの選択が反転され、要求されていないすべてのフィールドが表示されます。最後のコマンドを繰り返しますが、フィールド 7 のみを求めます。その後、そのコマンドを--complementオプションで再度実行します。
grep "/bin/bash" /etc/passwd | cut -d':' -f7
grep "/bin/bash" /etc/passwd | cut -d':' -f7 --complement
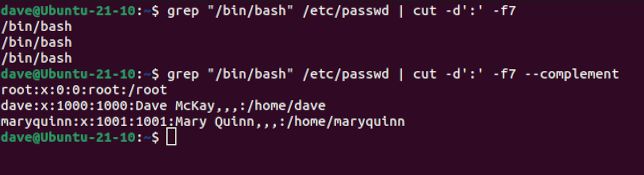
最初のコマンドはエントリのリストを検索しますが、フィールド 7 にはそれらを区別する情報がないため、エントリが何を指しているのかわかりません。2 番目のコマンドでは、--complementオプションを追加することで、フィールド 7 を除くすべてを取得します。
cut を cut にパイプする
"/etc/passwd" ファイルを維持したまま、フィールド 5 を抽出します。これは、ユーザーアカウントを所有するユーザーの実際の名前です。
grep "/bin/bash" /etc/passwd | cut -d':' -f5
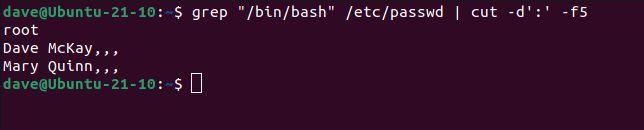
5 番目のフィールドには、コンマで区切られたサブフィールドがあります。それらはほとんど入力されないため、コンマの行として表示されます。
前のコマンドの出力を別のcutの呼び出しにパイプすることで、コンマを削除できます。cutの 2 番目のインスタンスはコンマ「,」を区切り文字として使用します。-s(区切り文字のみ)オプションは、区切り文字がまったく含まれていない結果をcutで抑制するように指示します。
grep "/bin/bash" /etc/passwd | cut -d':' -s -f5 | cut -d',' -s -f1

ルートエントリの 5 番目のフィールドにコンマ区切りのサブフィールドがないため、抑制され、目的の結果が得られます。つまり、このコンピュータで構成されている「実際の」ユーザーの名前のリストです。
出力区切り文字
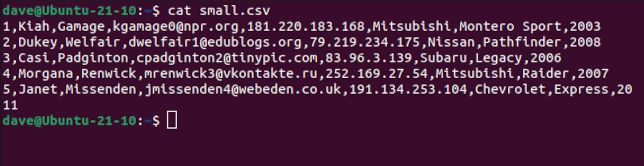
コンマ区切りの値を含む小さなファイルがあります。このダミーデータのフィールドは以下のとおりです。
- ID: データベース ID 番号
- First: 被験者の名。
- Last: 被験者の姓。
- email: メールアドレス。
- IP Address: IP アドレス。
- Brand: 彼らが運転する自動車のブランド。
- Model: 彼らが運転する自動車のモデル。
- Year: 自動車が製造された年。
cat small.csv
cut にコンマを区切り文字として使用するように指示すると、以前と同じようにフィールドを抽出できます。ファイルからデータを抽出する必要がある場合がありますが、結果にフィールド区切り文字を含めたくない場合があります。--output-delimiterを使用すると、cut に実際の区切り文字の代わりにどの文字(または文字シーケンス)を使用するかを指示できます。
cut -d ',' -f 2,3 small.csv
cut -d ',' -f 2,3 small.csv --output-delimiter=' '
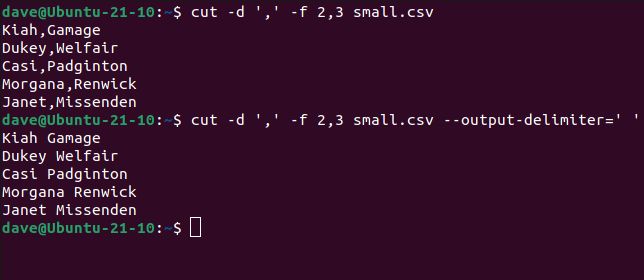
2 番目のコマンドは、cutにコンマをスペースに置き換えるように指示します。
さらに進んで、この機能を使用して出力を縦リストに変換できます。このコマンドでは、改行文字を出力区切り文字として使用します。改行文字が動作するように、そして 2 文字の文字列として解釈されないようにするために含める必要がある「$」に注意してください。
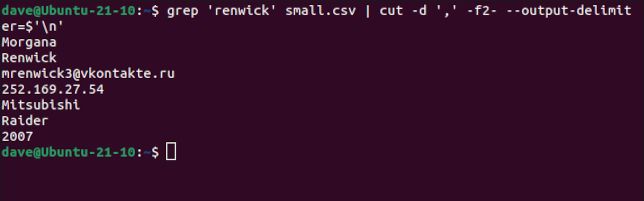
grepを使用して、モーガナ・レンウィックのエントリをフィルタリングし、cutにフィールド 2 からレコードの最後まですべてのフィールドを印刷し、改行文字を出力区切り文字として使用するように要求します。
grep 'renwick' small.csv | cut -d ',' -f2- --output-delimiter=$''
古くて新しい
執筆時点で、小さな cut コマンドは 40 歳を迎えようとしており、今日でも使用して記事を書いています。おそらく、今日のテキストの切り取り方は 40 年前と同じでしょう。つまり、適切なツールを手にすれば、はるかに簡単です。
コメントする