Linux のcurlコマンドは、ファイルをダウンロードする以外にもさまざまなことができます。curlが何ができるのか、wgetの代わりにいつ使用すべきかを学びましょう。
curl と wget: 違いは?
人々は、wgetとcurlコマンドの相対的な強みを識別することに苦労することがよくあります。これらのコマンドには機能的な重複があります。どちらのコマンドもリモートの場所からファイルを抽出できますが、類似点はここまでです。
wgetは、コンテンツとファイルをダウンロードするための素晴らしいツールです。ファイル、ウェブページ、ディレクトリをダウンロードできます。ウェブページのリンクをたどり、ウェブサイト全体でコンテンツを再帰的にダウンロードするためのインテリジェントなルーチンが含まれています。コマンドラインのダウンロードマネージャーとしては他に類を見ません。
curlは、まったく異なるニーズを満たします。はい、ファイルを抽出できますが、コンテンツを抽出するためにウェブサイトを再帰的にナビゲートすることはできません。curlが実際にできることは、それらのシステムにリクエストを行い、それらのシステムの応答を取得して表示することによって、リモートシステムと対話できるようにすることです。これらの応答はウェブページのコンテンツとファイルである可能性がありますが、curl リクエストによる「質問」の結果としてウェブサービスまたは API を介して提供されるデータを含めることもできます。
そして、curlはウェブサイトに限定されません。curlは、HTTP、HTTPS、SCP、SFTP、FTP を含む 20 以上のプロトコルをサポートしています。そして、Linux パイプの優れた処理により、curlは他のコマンドやスクリプトとより簡単に統合できると主張できます。
curlの作者は、curlとwgetの違いについて説明したウェブページを持っています。
curl のインストール
この記事を調査するために使用したコンピュータのうち、Fedora 31 と Manjaro 18.1.0 にはcurlがすでにインストールされていました。curlは Ubuntu 18.04 LTS にインストールする必要がありました。Ubuntu では、次のコマンドを実行してインストールします:
sudo apt-get install curl

curl のバージョン
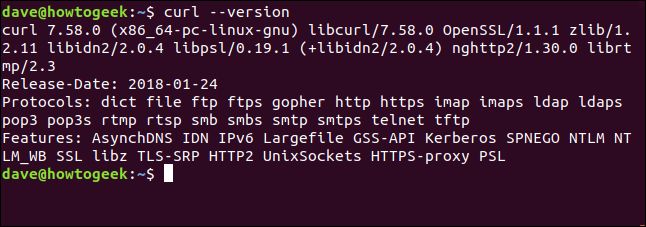
--versionオプションにより、curlはバージョンを報告します。また、サポートしているすべてのプロトコルも一覧表示します。
curl --version
ウェブページの抽出
curlをウェブページに向けると、ウェブページが抽出されます。
curl https://www.bbc.com

しかし、デフォルトのアクションはそれをソースコードとしてターミナルウィンドウにダンプすることです。
注意: curlに何かをファイルとして保存することを指示しない場合、常にターミナルウィンドウにダンプされます。抽出しているファイルがバイナリファイルの場合、結果は予測できません。シェルは、バイナリファイル内のバイト値の一部を制御文字またはエスケープシーケンスとして解釈しようとする可能性があります。
データをファイルに保存する
curl に出力をファイルにリダイレクトするように指示してみましょう:
curl https://www.bbc.com > bbc.html

今回は抽出された情報が表示されず、私たちのためにファイルに直接送信されます。ターミナルウィンドウに表示する出力がないため、curlは進捗情報のセットを出力します。
これは、進捗情報がウェブページのソースコード全体に分散されていたため、curlが自動的に抑制されたため、以前の例では行いませんでした。
この例では、curlは出力がファイルにリダイレクトされていること、および進捗情報を生成することが安全であることを検出します。
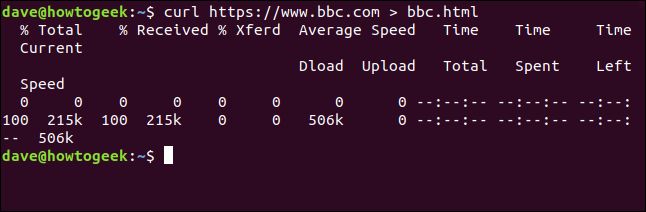
提供される情報は次のとおりです:
- 合計%: 抽出する合計量。
- 受信%: これまでに抽出されたデータのパーセンテージと実際の値。
- 転送%: データがアップロードされている場合、転送されたパーセンテージと実際の値。
- 平均速度Dload: 平均ダウンロード速度。
- 平均速度Upload: 平均アップロード速度。
- 合計時間: 転送の推定合計時間。
- 経過時間: これまでのこの転送の経過時間。
- 残り時間: 転送が完了するまでの推定時間。
- 現在の速度: この転送の現在の転送速度。
curlからの出力をファイルにリダイレクトしたため、現在は「bbc.html」というファイルがあります。
そのファイルをダブルクリックすると、デフォルトのブラウザが開き、抽出されたウェブページが表示されます。
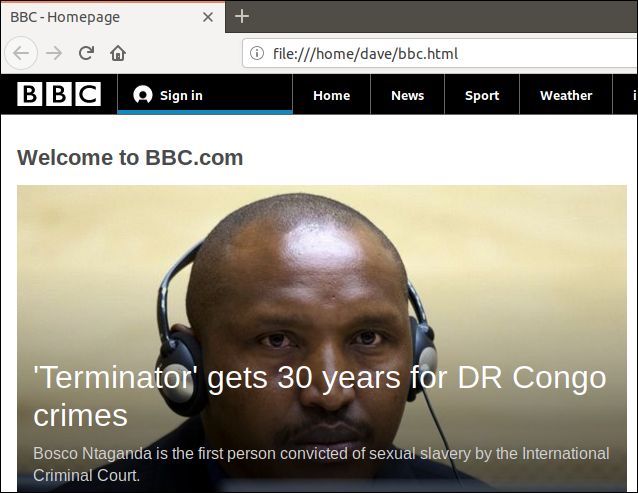
ブラウザのアドレスバーのアドレスは、リモートウェブサイトではなく、このコンピュータ上のローカルファイルであることに注意してください。
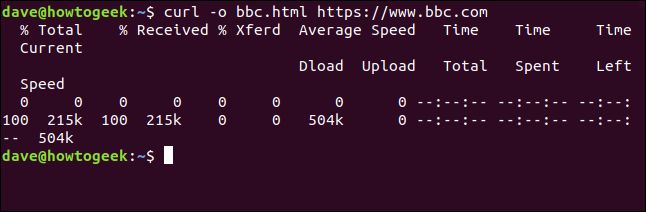
出力をリダイレクトしなくても、ファイルを作成できます。-o(出力) オプションを使用してファイルを作成し、curlにファイルを作成するように指示できます。ここでは、-oオプションを使用し、作成するファイルの名前「bbc.html」を指定しています。
curl -o bbc.html https://www.bbc.com
進行状況バーを使用してダウンロードを監視する
テキストベースのダウンロード情報をシンプルな進行状況バーに置き換えるには、-#(進行状況バー) オプションを使用します。
curl -x -o bbc.html https://www.bbc.com

中断されたダウンロードを再開する
終了または中断されたダウンロードを再開するのは簡単です。かなりのサイズのファイルのダウンロードを開始してみましょう。Ubuntu 18.04 の最新の長期サポートビルドを使用します。--outputオプションを使用して、保存するファイルの名前を「ubuntu180403.iso」として指定します。
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

ダウンロードが開始され、完了に向けて進みます。
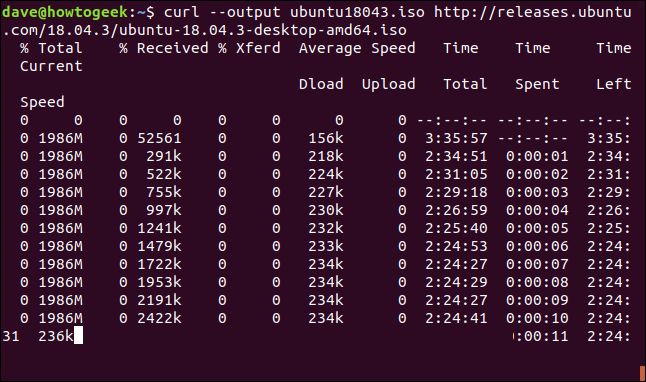
Ctrl+Cでダウンロードを強制的に中断すると、コマンドプロンプトに戻り、ダウンロードは中止されます。
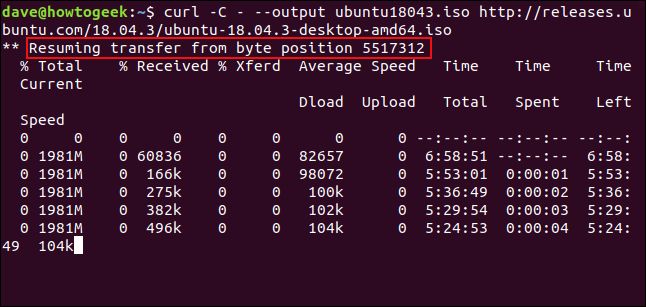
ダウンロードを再開するには、-C(at で続行) オプションを使用します。これにより、curlはターゲットファイル内の指定されたポイントまたはオフセットでダウンロードを再開します。オフセットとしてハイフン-を使用すると、curlはファイルのダウンロード済み部分を見て、それ自体に使用する正しいオフセットを決定します。
curl -C - --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

ダウンロードが再開されます。curlは再開するオフセットを報告します。
HTTP ヘッダーを取得する
-I(head) オプションを使用すると、HTTP ヘッダーのみを取得できます。これは、HTTP HEAD コマンドを Web サーバーに送信するのと同じです。
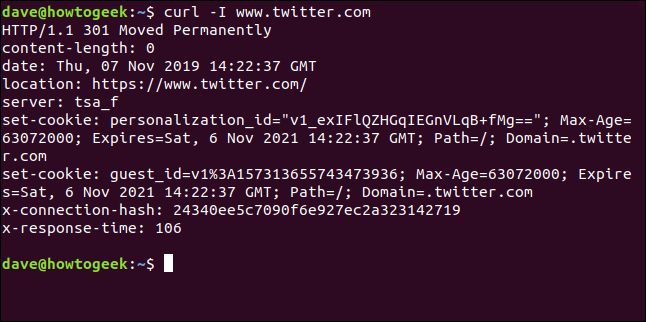
curl -I www.twitter.com

このコマンドは情報のみを取得し、ウェブページやファイルはダウンロードしません。
複数の URL をダウンロードする
xargsを使用すると、複数の URL を同時にダウンロードできます。おそらく、単一の記事やチュートリアルを構成する一連のウェブページをダウンロードしたいと思うでしょう。
これらの URL をエディターにコピーして、「urls-to-download.txt」というファイルに保存します。xargsを使用して、テキストファイルの各行の内容をパラメータとして扱い、それをcurlに順番に渡すことができます。
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
xargsがこれらの URL をcurlに 1 つずつ渡すために使用する必要があるコマンドは次のとおりです。
xargs -n 1 curl -O < urls-to-download.txt
このコマンドは、大文字の「O」を使用する-O(リモートファイル) 出力コマンドを使用することに注意してください。このオプションにより、curlは、リモートサーバー上のファイルと同じ名前で取得したファイルを保存します。
-n 1オプションは、xargsにテキストファイルの各行を単一のパラメータとして扱うように指示します。
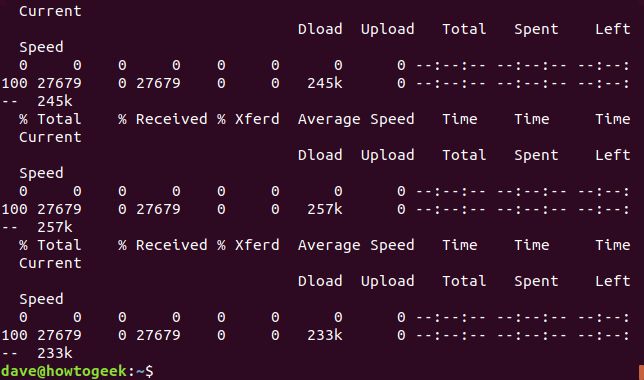
コマンドを実行すると、複数のダウンロードが次々と開始され、終了します。
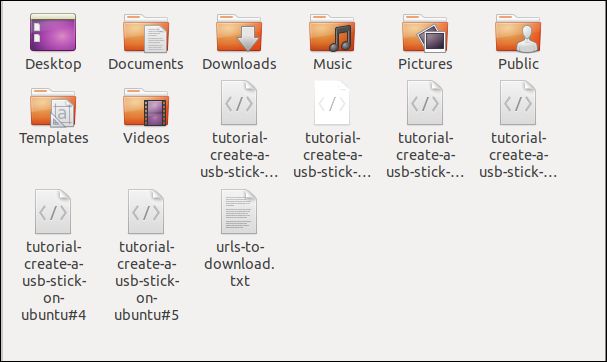
ファイルブラウザで確認すると、複数のファイルがダウンロードされていることがわかります。それぞれが、リモートサーバー上の名前を保持しています。
FTP サーバーからファイルをダウンロードする
ユーザー名とパスワードで認証する必要がある場合でも、curlをファイル転送プロトコル (FTP) サーバーで使用するのは簡単です。curlでユーザー名とパスワードを渡すには、-u(ユーザー) オプションを使用し、ユーザー名、コロン「:」、パスワードを入力します。コロンの前後にスペースを入れないでください。
これは、Rebex がホストするテスト用の無料 FTP サーバーです。テスト用の FTP サイトには、「demo」という事前設定されたユーザー名があり、パスワードは「password」です。本番環境または「実際の」FTP サーバーでは、この種の弱いユーザー名とパスワードを使用しないでください。
curl -u demo:password ftp://test.rebex.net

curlは、FTP サーバーを指していることを検出し、サーバーにあるファイルのリストを返します。

このサーバー上の唯一のファイルは、長さ 403 バイトの「readme.txt」ファイルです。取得してみましょう。少し前のコマンドと同じコマンドを使用し、ファイル名を付加します:
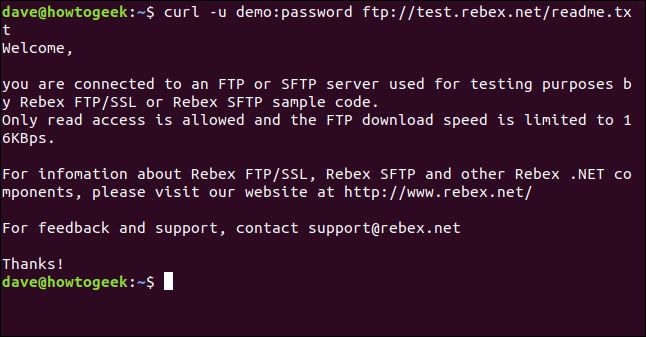
curl -u demo:password ftp://test.rebex.net/readme.txt

ファイルが取得され、curlはターミナルウィンドウにその内容を表示します。
ほとんどの場合、取得したファイルをターミナルウィンドウに表示するのではなく、ディスクに保存しておく方が便利です。再度、-O(リモートファイル) 出力コマンドを使用して、リモートサーバー上のファイル名と同じファイル名を付けてディスクにファイルを保存できます。
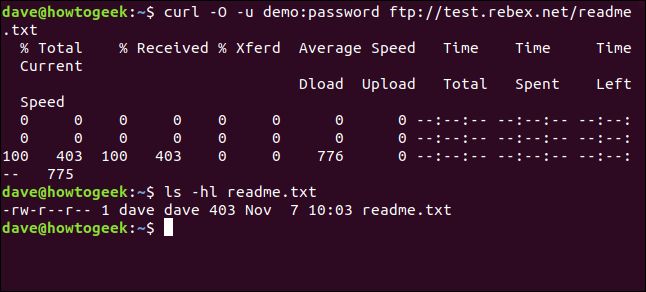
curl -O -u demo:password ftp://test.rebex.net/readme.txt

ファイルが取得され、ディスクに保存されます。lsを使用してファイルの詳細を確認できます。FTP サーバー上のファイルと同じ名前を持ち、同じ長さ (403 バイト) です。
ls -hl readme.txt
リモートサーバーにパラメータを送信する
一部のリモートサーバーは、送信されたリクエスト内のパラメータを受け入れます。パラメータは、返されるデータの書式設定に使用される場合もあれば、ユーザーが取得したい正確なデータを選択するために使用される場合もあります。curlを使用して Web アプリケーションプログラミングインターフェイス (API) と対話できることがよくあります。
簡単な例として、ipify Web サイトには、外部 IP アドレスを確認するために照会できる API があります。
curl https://api.ipify.org
値が「json」のコマンドにformatパラメータを追加することで、再度外部 IP アドレスを要求できますが、今回は返されるデータは JSON 形式でエンコードされます。
curl https://api.ipify.org?format=json

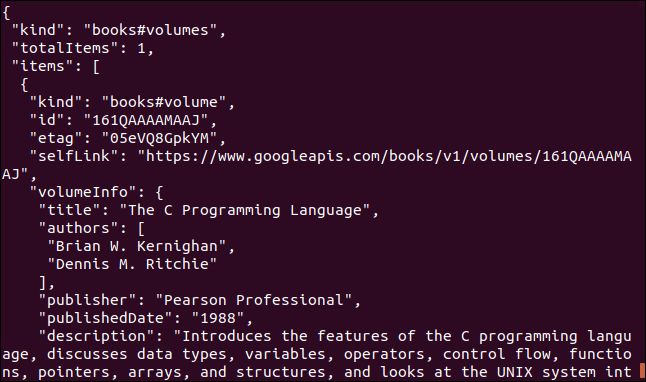
Google API を使用する別の例を紹介します。これは、本を説明する JSON オブジェクトを返します。提供する必要があるパラメータは、本の国際標準図書番号 (ISBN) 番号です。ISBN は、ほとんどの本の後表紙にバーコードの下に記載されています。ここで使用するパラメータは「0131103628」です。
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628

返されるデータは包括的です:
場合によっては curl、場合によっては wget
Web サイトからコンテンツをダウンロードし、そのコンテンツを再帰的に検索して Web サイトのツリー構造を取得したい場合は、wgetを使用します。
リモートサーバーまたは API と対話し、ファイルやウェブページをダウンロードしたい場合は、curlを使用します。特に、プロトコルがwgetでサポートされていないものの 1 つである場合です。
関連記事: 開発者や愛好家におすすめの Linux ノート PC
コメントする