Web スクレイピングは、Web サイトから情報を抽出して自動的に分析する強力な手法です。手動で行うこともできますが、面倒で時間がかかる作業になる可能性があります。Web スクレイピング ツールを使用すると、コストを抑えながら、より迅速かつ効率的にプロセスを実行できます。
興味深いことに、Google スプレッドシートは、IMPORTXML 関数のおかげで、ワンストップの Web スクレイピング ツールになる可能性を秘めています。IMPORTXML を使用すると、Web ページからデータを簡単にスクレイピングして、分析、レポート、またはその他のデータ主導のタスクに使用できます。
Google スプレッドシートの IMPORTXML 関数
Google スプレッドシートには、IMPORTXML という組み込み関数が用意されており、XML、HTML、RSS、CSV などの Web 形式からデータをインポートできます。複雑なコーディングに頼らずに Web サイトからデータを収集したい場合、この関数はゲームチェンジャーになる可能性があります。
IMPORTXML の基本的な構文を次に示します。
=IMPORTXML(url, xpath_query)
- url: データをスクレイピングする Web ページの URL。
- xpath_query: 抽出するデータを定義する XPath クエリ。
XPath (XML Path Language) は、HTML を含む XML ドキュメントをナビゲートするために使用される言語であり、HTML 構造内のデータの場所を指定できます。IMPORTXML を適切に使用するには、XPath クエリを理解することが不可欠です。
XPath の理解
XPath は、HTML ドキュメント内のデータをナビゲートしてフィルタリングするためのさまざまな関数と式を提供します。この記事では XML と XPath の包括的なガイドを説明する範囲を超えているため、XPath の基本的な概念について説明します。
- 要素の選択:要素を選択するには、/と//を使用してパスを示すことができます。たとえば、/html/body/divは、ドキュメントの本文にあるすべての div 要素を選択します。
- 属性の選択: 属性を選択するには、@を使用できます。たとえば、//@hrefは、ページ上のすべてのhref属性を選択します。
- 述語フィルタ: 角かっこ ([ ]) で囲まれた述語を使用して、要素をフィルタリングできます。たとえば、/div[@class="container"]は、クラスcontainerを持つすべてのdiv要素を選択します。
- 関数: XPath は、contains()、starts-with()、text()などのさまざまな関数を提供して、テキスト コンテンツや属性値の確認などの特定のアクションを実行します。
Web サイトから XPath を抽出する方法
これまでに、IMPORTXML の構文、Web サイトの URL、抽出する要素がわかりました。しかし、要素の XPath を取得するにはどうすればよいでしょうか?
IMPORTXML でデータを抽出するために、Web サイトの構造をすべて暗記する必要はありません。実際、どのブラウザにも、任意の要素の XPath をすぐにコピーできる便利なツールが備わっています。
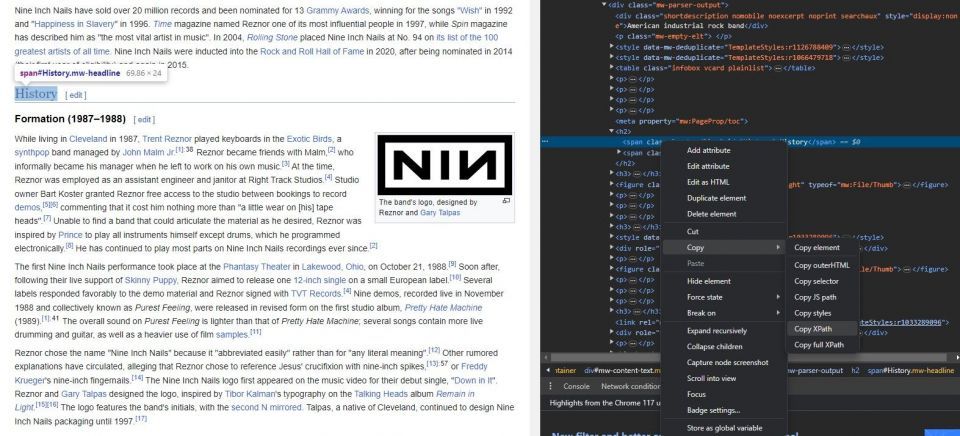
要素を調べるツールを使用すると、Web サイトの要素から XPath を抽出できます。方法を次に示します。
- お気に入りの Web ブラウザを使用して、スクレイピングする Web ページに移動します。
- スクレイピングする要素を見つけます。
- 要素を右クリックします。
- 右クリック メニューから要素を調べるを選択します。ブラウザは、Web ページの HTML コードを表示するパネルを開きます。関連する HTML 要素がコード内でハイライト表示されます。
- 要素を調べるパネルで、HTML コード内でハイライト表示されている要素を右クリックします。
- XPath をコピーをクリックして、要素の XPath アドレスをクリップボードにコピーします。
これで必要なものがすべて揃ったので、IMPORTXML を実際に使用してリンクをスクレイピングしてみましょう。
IMPORTXML を使用して Web サイトからリンクをスクレイピングする方法
IMPORTXML を使用すると、Web サイトからあらゆる種類のデータをスクレイピングできます。これには、リンク、ビデオ、画像、Web サイトのほぼすべての要素が含まれます。リンクは Web 分析で最も重要な要素の 1 つであり、リンク先のページを分析するだけで、Web サイトについて多くのことを学ぶことができます。
IMPORTXML を使用すると、Google スプレッドシートでリンクをすばやくスクレイピングし、Google スプレッドシートが提供するさまざまな関数を使用してさらに分析できます。
1. すべてのリンクのスクレイピング
Web ページからすべてのリンクをスクレイピングするには、次の数式を使用できます。
=IMPORTXML(url, "//a/@href")
この XPath クエリは、a要素のすべてのhref属性を選択し、ページ上のすべてのリンクを効果的に抽出します。
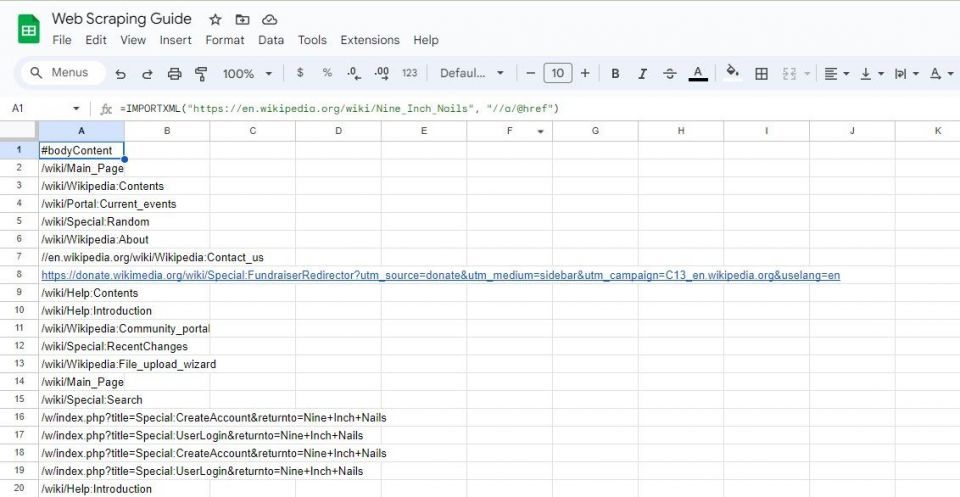
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
上の数式は、Wikipedia の記事内のすべてのリンクをスクレイピングします。
Web ページの URL を別のセルに入力してから、そのセルを参照することをお勧めします。これにより、数式が長くなりすぎて扱いにくくなるのを防ぐことができます。XPath クエリでも同じことができます。
2. すべてのリンク テキストのスクレイピング
リンクのテキストとその URL を抽出するには、次を使用できます。
=IMPORTXML(url, "//a")
このクエリは、すべての要素を選択し、結果からリンク テキストと URL を抽出できます。
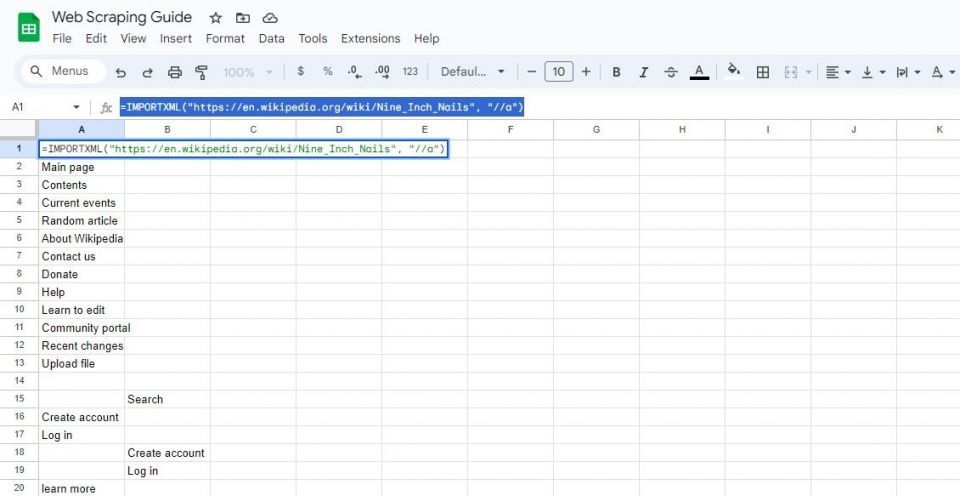
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
上の数式は、同じ Wikipedia の記事内のリンク テキストを取得します。
IMPORTXML を使用して Web サイトから特定のリンクをスクレイピングする方法
特定の条件に基づいて特定のリンクをスクレイピングする必要がある場合があります。たとえば、特定のキーワードを含むリンクや、ページの特定のセクションにあるリンクを抽出したい場合があります。
XPath に関する十分な知識があれば、探している要素を特定できます。
1. キーワードを含むリンクのスクレイピング
特定のキーワードを含むリンクをスクレイピングするには、contains() XPath 関数を使用できます。
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
このクエリは、href に指定されたキーワードが含まれている要素の href 属性を選択します。
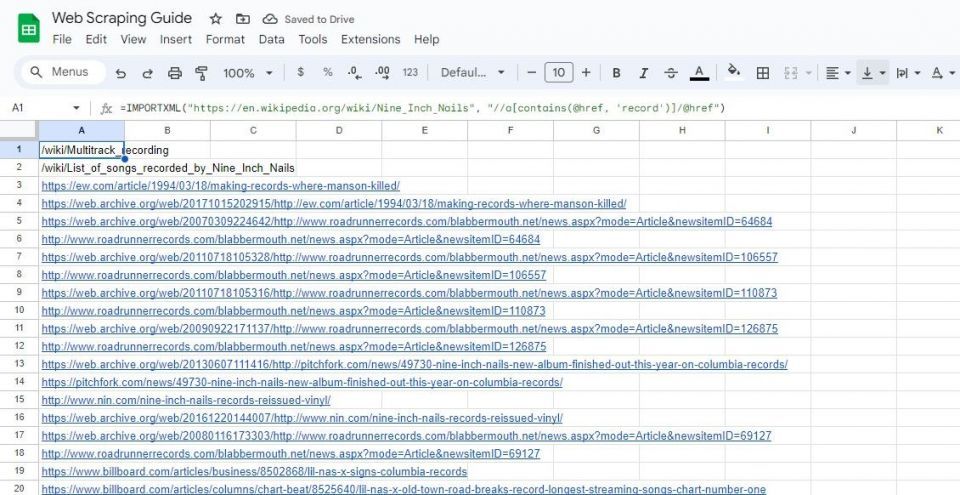
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
上の数式は、サンプルの Wikipedia の記事内でテキストに単語 record を含むすべてのリンクをスクレイピングします。
2. セクション内のリンクのスクレイピング
ページの特定のセクションからリンクをスクレイピングするには、セクションの XPath を指定できます。たとえば:
=IMPORTXML(url, "//div[@class='section']//a/@href")
このクエリは、クラスが「section」の div 要素内の要素の href 属性を選択します。
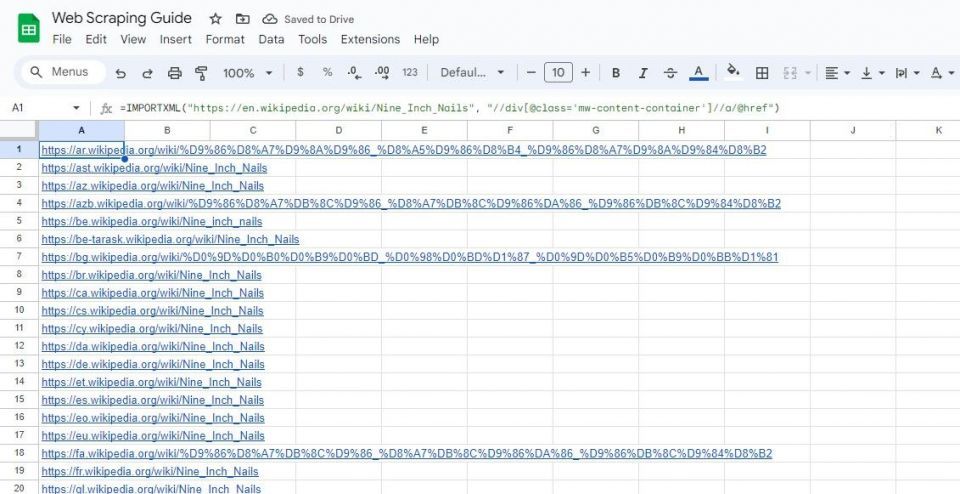
同様に、下の数式は、mw-content-container クラスを持つ div クラス内のすべてのリンクを選択します:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class='mw-content-container']//a/@href")
IMPORTXML は Web スクレイピング以外にも使用できることに注意してください。IMPORT ファミリの関数は、Web サイトから Google スプレッドシートにデータ テーブルをインポートするために使用できます。
Google スプレッドシートと Excel はほとんどの機能を共有していますが、IMPORT ファミリの関数は Google スプレッドシートに固有です。Web サイトから Excel にデータをインポートするには、他の方法を検討する必要があります。
Google スプレッドシートで Web スクレイピングを簡素化
Google スプレッドシートと IMPORTXML 関数を使用した Web スクレイピングは、Web サイトからデータを収集するための汎用的でアクセスしやすい方法です。
XPath をマスターし、効果的なクエリを作成する方法を理解することで、IMPORTXML の可能性を最大限に引き出し、Web リソースから貴重な洞察を得ることができます。スクレイピングを開始して、Web 分析を次のレベルに引き上げましょう!
コメントする