概要
- Nvidia Chat with RTX は、TensorRT-LLM と RAG を使用してパーソナライズされた応答を提供する、お使いの PC でローカルに実行される AI チャットボットです。
- Chat with RTX をインストールするには、次の最低要件が必要です: RTX GPU、16GB RAM、100GB ストレージ、Windows 11。
- Chat with RTX を使用して、RAG 用のファイルを設定し、質問をし、YouTube 動画を分析し、データのセキュリティを確保します。
Nvidia は、お使いの PC で動作し、ChatGPTなどと同様の機能を提供する AI チャットボットである Chat with RXT を発売しました。必要なのは Nvidia RTX GPU だけです。Nvidia の新しい AI チャットボットの使用を開始できます。
Nvidia Chat with RTX とは何ですか?
Nvidia Chat with RTX は、お使いのコンピューターでローカルに大規模言語モデル (LLM) を実行できる AI ソフトウェアです。つまり、ChatGPTのような AI チャットボットを使用するためにオンラインになるのではなく、いつでもオフラインで Chat with RTX を使用できます。
Chat with RTX は、TensorRT-LLM、RTX アクセラレーション、量子化された Mistral 7-B LLM を使用して、他のオンライン AI チャットボットと同等の高速なパフォーマンスと高品質な応答を提供します。また、検索結果の追加生成 (RAG) が提供されており、チャットボットはファイルを読み取って、提供されたデータに基づいてカスタマイズされた回答を可能にします。これにより、よりパーソナルなエクスペリエンスを提供するためにチャットボットをカスタマイズできます。
Nvidia Chat with RTX を試してみたい場合は、次の方法でコンピューターにダウンロード、インストール、構成します。
Chat with RTX のダウンロードとインストール方法

Nvidia は、お使いのコンピューターで LLM をローカルで実行することをはるかに簡単にしました。Chat with RTX を実行するには、他のソフトウェアと同様にアプリをダウンロードしてインストールするだけです。ただし、Chat with RTX には、適切にインストールして使用するのに最低限の仕様要件があります。
- RTX 30 シリーズまたは 40 シリーズ GPU
- 16GB RAM
- 100GB の空きメモリ容量
- Windows 11
お使いの PC が最低システム要件を満たしている場合は、アプリをインストールできます。
- ステップ 1:Chat with RTX ZIP ファイルをダウンロードします。
- ダウンロード:Chat with RTX (無料 - 35GB のダウンロード)
- ステップ 2:ZIP ファイルを右クリックして 7Zip などのファイルアーカイブツールを選択するか、ファイルをダブルクリックしてすべて展開を選択して展開します。
- ステップ 3:展開されたフォルダーを開き、setup.exeをダブルクリックします。画面の指示に従い、カスタムインストールプロセス中にすべてのボックスにチェックを入れます。次へをクリックすると、インストーラーは LLM とすべての依存関係をダウンロードしてインストールします。
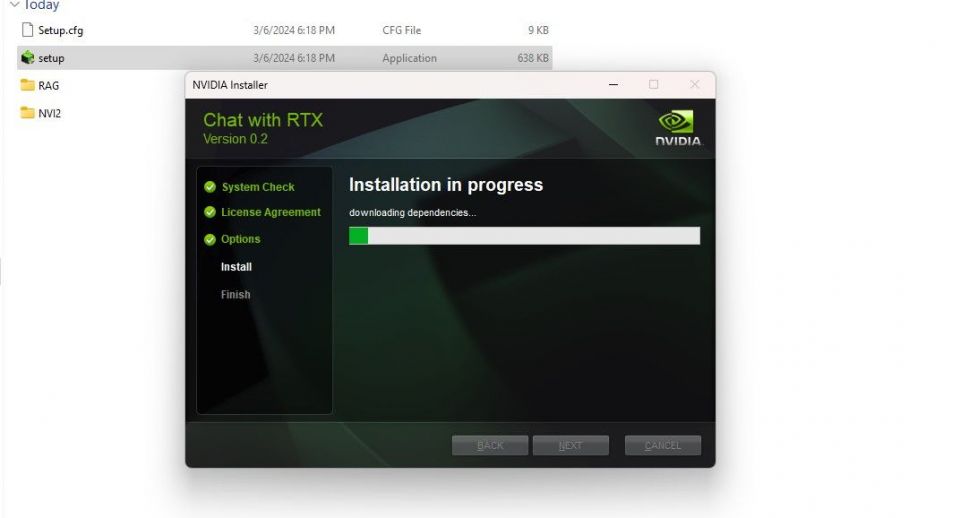
Chat with RTX のインストールは、大量のデータをダウンロードしてインストールするため、完了するまで時間がかかります。インストールプロセスが完了したら、閉じるをクリックすると完了です。これで、アプリを試すことができます。
Nvidia Chat with RTX の使用方法
通常のオンライン AI チャットボットのように Chat with RTX を使用できますが、アクセスを許可したファイルに基づいて出力をカスタマイズできる RAG 機能を確認することを強くお勧めします。
ステップ 1: RAG フォルダーを作成する
Chat with RTX で RAG を使用するには、 AI が分析するファイル用の新しいフォルダーを作成します。
作成後、データファイルをフォルダーに配置します。保存するデータは、ドキュメント、PDF、テキスト、動画など、さまざまなトピックとファイルタイプをカバーできます。ただし、パフォーマンスに影響を与えないように、このフォルダーに配置するファイルの数を制限することをお勧めします。検索するデータが多いほど、Chat with RTX は特定のクエリに対する応答を返すのに時間がかかります (ただし、これはハードウェアにも依存します)。
データベースの準備が整ったので、Chat with RTX を設定して、質問やクエリに答えるために使用できます。
ステップ 2: 環境を設定する
Chat with RTX を開きます。次の画像のようになっているはずです。

データセットの下で、フォルダーパスオプションが選択されていることを確認します。次に、下の編集アイコン (ペンアイコン) をクリックし、Chat with RTX に読み取らせたいすべてのファイルを含むフォルダーを選択します。他のオプションが利用可能な場合は、 AI モデルを変更することもできます (執筆時点では、Mistral 7B のみ利用可能)。
これで Chat with RTX を使用できるようになりました。
ステップ 3: Chat with RTX に質問する!
Chat with RTX にクエリを実行する方法はいくつかあります。1 つ目は、通常の AI チャットボットのように使用することです。私は Chat with RTX にローカル LLM を使用することの利点について尋ね、その回答に満足しました。非常に詳細ではありませんでしたが、十分に正確でした。

しかし Chat with RTX は RAG が使用できるため、パーソナル AI アシスタントとしても使用できます。

上記では、Chat with RTX を使用して自分のスケジュールについて尋ねています。データは、スケジュール、カレンダー、イベント、仕事などを含む PDF ファイルから取得されました。この場合、Chat with RTX はデータから正しいカレンダー データを抽出しています。このような機能を適切に機能させるには、データ ファイルとカレンダーの日付を最新の状態に保つ必要があります。ただし、他のアプリとの統合が行われるまでは。
Chat with RTX の RAG を活用できる方法は数多くあります。たとえば、法的書類を読み取って要約を作成したり、開発中のプログラムに関連するコードを生成したり、視聴する時間がなさすぎる動画の箇条書きのハイライトを取得したりできます。他にもたくさんあります!
ステップ 4: ボーナス機能
ローカル データ フォルダーに加えて、Chat with RTX を使用して YouTube 動画を分析できます。これを行うには、データセットの下でフォルダーパスをYouTube URLに変更します。

分析したい YouTube URL をコピーして、ドロップダウン メニューの下に貼り付けます。その後、質問してください!
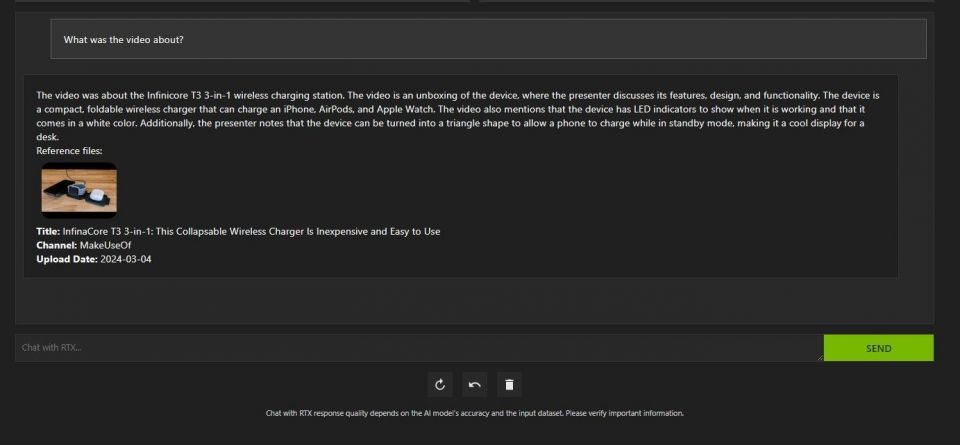
Chat with RTX の YouTube 動画分析は非常に優れており、正確な情報を提供するため、調査、迅速な分析などに役立ちます。
Nvidia の Chat with RTX は優れていますか?
ChatGPTは RAG 機能を提供します。一部のローカル AI チャットボットは、システム要件が大幅に低くなっています。では、Nvidia Chat with RTX を使用する価値はありますか?
答えはイエスです! Chat with RTX は、競合他社があるにもかかわらず使用する価値があります。
Nvidia Chat with RTX を使用することの最大のセールスポイントの 1 つは、ファイルをサードパーティのサーバーに送信せずに RAG を使用できることです。GPTをオンライン サービスでカスタマイズすると、データが公開される可能性があります。しかし、Chat with RTX はローカルでインターネット接続なしで実行されるため、Chat with RTX で RAG を使用すると、機密データが安全に保護され、PC 上でのみアクセスできるようになります。
Mistral 7B を実行する他のローカル実行 AI チャットボットに関しては、Chat with RTX のパフォーマンスがより優れており、高速です。パフォーマンスの向上の大部分はハイエンド GPU の使用によるものですが、Nvidia TensorRT-LLM と RTX アクセラレーションを使用すると、チャットに最適化された LLM を実行する他の方法と比較して、Chat with RTX で Mistral 7B をより高速に実行できます。
現在使用している Chat with RTX バージョンはデモであることに注意してください。Chat with RTX の後続のリリースでは、さらに最適化され、パフォーマンスが向上する可能性があります。
RTX 30 または 40 シリーズ GPU がない場合はどうすればよいですか?
Chat with RTX は、インターネット接続を必要とせずに LLM をローカルで実行するための簡単、高速、安全な方法です。また、LLM を実行することに興味があるが、RTX 30 または 40 シリーズ GPU がない場合は、他の方法で LLM をローカルで実行できます。最も人気のある 2 つはGPT4ALL と Text Gen WebUI です。LLM をローカルでプラグアンドプレイで実行したい場合は、GPT4ALL を試してください。しかし、技術的に少し詳しい場合は、Text Gen WebUI を介して LLM を実行すると、より優れた微調整と柔軟性を得られます。
コメントする